
- Difference between Artificial Intelligence and Machine Learning | Everything You Need to Know
- How Quantum Computing Will Transform Cybersecurity | All you need to know [ OverView ]
- What is Design Thinking? : 5 Stages in the Design Thinking Process [OverView]
- What is Design Thinking Model?
- The Top 5 Technology Trend Creators | All you need to know [ OverView ]
- AI vs Data Science: Mapping Your Career Path [ Job & Future ]
- What is Computer Vision & How does it Works ? : Everything You Need to Know [ OverView ]
- What is TensorFlow? : Expert’s Top Picks | Everything You Need to Know
- Keras vs Tensorflow vs Pytorch | Difference You Should Know
- Advantages and Disadvantages of Artificial Intelligence
- What are the Deep Learning Algorithms You Should Know About?
- The Rise of Artificial Intelligence and Machine Learning Job Trends
- Top 5 Jobs In AI and Key Skills Needed To Help You Land One
- Top AI and Machine Learning Trends for 2020
- How to Build a Career in AI and Machine Learning?
- Artificial Intelligence for Beginners
- What Is Emotional Intelligence and Its Importance?
- What Is Artificial Neural Networks?
- Top Real World Artificial Intelligence Applications
- What is Artificial Intelligence?
- Difference between Artificial Intelligence and Machine Learning | Everything You Need to Know
- How Quantum Computing Will Transform Cybersecurity | All you need to know [ OverView ]
- What is Design Thinking? : 5 Stages in the Design Thinking Process [OverView]
- What is Design Thinking Model?
- The Top 5 Technology Trend Creators | All you need to know [ OverView ]
- AI vs Data Science: Mapping Your Career Path [ Job & Future ]
- What is Computer Vision & How does it Works ? : Everything You Need to Know [ OverView ]
- What is TensorFlow? : Expert’s Top Picks | Everything You Need to Know
- Keras vs Tensorflow vs Pytorch | Difference You Should Know
- Advantages and Disadvantages of Artificial Intelligence
- What are the Deep Learning Algorithms You Should Know About?
- The Rise of Artificial Intelligence and Machine Learning Job Trends
- Top 5 Jobs In AI and Key Skills Needed To Help You Land One
- Top AI and Machine Learning Trends for 2020
- How to Build a Career in AI and Machine Learning?
- Artificial Intelligence for Beginners
- What Is Emotional Intelligence and Its Importance?
- What Is Artificial Neural Networks?
- Top Real World Artificial Intelligence Applications
- What is Artificial Intelligence?

What is Computer Vision & How does it Works ? : Everything You Need to Know [ OverView ]
Last updated on 03rd Nov 2022, Artciles, Artificial Intelligence, Blog
- In this article you will get
- Preface to Computer Vision
- Moment, numerous effects have changed for the good of computer vision
- Where is Computer Vision used?
- How does Computer Vision work?
- Convolutional Neural Networks( CNNs)
- Top Tools used for Computer Vision
- Conclusion
Preface to Computer Vision
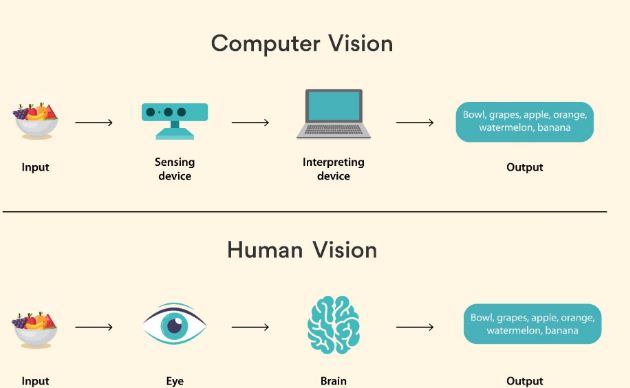
Since the morning of life, mortal vision has been essential, beautiful and complex. Until a decade agone machines were n’t suitable to perceive the visual world as efficiently as we used to.Computer vision is an interdisciplinary scientific field that deals with how computers can perceive the visual world in the form of images and videos. From an engineering perspective, it seeks to replicate and automate tasks that can be performed by the mortal visual system.
Using digital images from cameras and videotape and deep literacy models, machines can directly identify and classify objects – and also reply to what they “ see ”.The thing is to give computers the capability to prize a high- position understanding of the visual world from digital images and videos.However, you know that computers are formerly good at landing images and videotape in inconceivable dedication and detail better than humans, If you ’ve used a digital camera or smartphone.
Moment, numerous effects have changed for the good of computer vision
- 1.Mobile technology with HD cameras has handed the world a vast collection of images and videos.
- 2.Computing power has grown and has come more fluently accessible and more affordable.
- 3.Specific tackle and tools designed for computer vision are more extensively available. We’ve bandied some of the tools lately in this composition.
These advances have been salutary to computer vision. delicacy rates for object recognition and brackets have grown from 50 to 99 over a decade, with the result that moment’s computers are more accurate and briskly than humans at detecting visual input.
Where is Computer Vision used?
1.Healthcare:
Computer vision is extensively used in healthcare. Medical opinion relies heavily on the study of images, reviews, and prints. Analysis of ultrasound images, MRIs and CT reviews are part of the standard force of ultramodern drugs, and computer vision technologies promise not only to simplify the process but also to help false judgments and reduce treatment costs. Huh. Computer vision isn’t intended to replace medical professionals, but to grease their work and support them in decision- timber. Image segmentation helps in opinion by relating applicable areas on a 2D or 3D checkup and coloring them to grease the study of black and white images.
2.Automotive Industry:
Tone- driving buses belong to the use cases in artificial intelligence and have entered the most media attention in recent times. This can presumably be explained more by the idea of independent driving being more futuristic than by the factual consequences of the technology itself. numerous machine literacy problems are fraught with it, but computer vision is an important core element in their result. For illustration, the algorithm( the so- called “ agent ”) by which the auto is controlled must be apprehensive of the auto’s terrain at all times.
3.Retail Tracking client Behavior:
Online stores like Amazon use the analytics capabilities of their digital platforms to assay client geste in detail and optimize stoner experience. The retail association is also trying to optimize and idealize the experience of its guests. Until now, tools to automatically capture the relations of people with the displayed particulars have been missing. Computer vision is now suitable to bridge this gap for retail assistance.
4.Agriculture:
Machine literacy is a rescuer because huge quantities of data can be generated using drones, satellite images and remote detectors. ultramodern technology facilitates the collection of colorful measured values, parameters and data, which can be covered automatically. Thus, despite extensive planting over large areas, growers have round- the- timepiece observation of soil conditions, irrigation situations, factory health and original temperatures. Machine literacy algorithms estimate this data so that growers can use this information to reply to implicit problem areas at an early stage and efficiently distribute available coffers.
The analysis of image material allows the discovery of factory conditions at an early stage. A many times agone factory conditions were frequently noticed only when they were formerly able to spread. wide spread can now be detected and averted at an early stage using early warning systems grounded on computer vision, which means less cropping in fields and savings on countermeasures similar as fungicides because of the relative generally small areas need to be treated.
How does Computer Vision work?
Images on computers are frequently stored as large grids of pixels. Each pixel is defined as a color, which is stored as a combination of 3 cumulative primary colors RGB( red green blue). Colors are stored inside pixels.For that, we ’ll take the RGB value of the middle pixel.After looking at each pixel, the stylish match is likely to be the pixel from the orange ball.
We can run this algorithm for every frame of the videotape and track the ball over time. But, if one of the brigades is wearing an orange jersey, the algorithm can get confused.Therefore, this approach doesn’t work for features larger than a single pixel, similar as the.For illustration, an algorithm that finds perpendicular edges in a scene, so that the drone can navigate safely through an area of obstacles. For this operation, a fine memorandum is used, which is called a kernel or sludge. It contains values for pixel-wise addition, the sum of which is saved in the center pixel.

Convolutional Neural Networks( CNNs)
An artificial neuron is the structure block of a neural network. It takes a series of inputs, and multiplies each by a specified weight, also sums those values up as a whole.The CNN uses these banks of neurons to reuse the image data, each producing a new image, basically digested by different learned kernels. These labors are also reused by posterior layers of neurons, allowing repeated complications.
The first convolutional subcaste can find effects like edges, the coming subcaste can convolve on the features of those edges to fete simple shapes made of edges, like edges. The coming subcaste can concentrate on those corner features, and contains neurons that can fete simple objects similar to mouths and eyebrows. This keeps repeating, erecting in complexity, until there’s a subcaste that makes a determination that recognizes all the features eyes, cognizance, mouth, nose,etc., and says “ this is a face ”.
Top Tools used for Computer Vision
Presently, there are colorful online tools that give algorithms for computer vision and a platform to execute these algorithms or produce new bones.These tools also give a terrain for engaging with colorful other software and technologies in confluence with computer vision.
1.OpenCV:
OpenCV( Open Source Computer Vision Library) is an open- source computer vision library that contains numerous different functions for computer vision and machine learning.Created by Intel and firstly released in 2000, OpenCV contains numerous different algorithms related to computer vision that discovery and discovery, object recognition, monitoring of moving objects, Can perform a variety of tasks, including tracking movements, tracking eye movements., rooting 3D models of objects, creating an stoked reality overlay with a scene, feting analogous images in an image database, etc. OpenCV has interfaces for C, Python, Java, MATLAB etc and supports colorful operating systems like Windows, Android., Mac OS, Linux,etc.
2.TensorFlow:
TensorFlow is a free open- source platform with a variety of tools, libraries, and coffers for artificial intelligence and machine literacy, including computer vision. It was created by the Google Brain platoon and was originally released on November 9, 2015. TensorFlow can be used to make and train machine literacy models related to computer vision including recognition, object recognition, etc. Google also released Pixel Visual Core( PVC) in 2017 which is an image, vision and artificial intelligence processor for mobile bias.TensorFlow supports languages. similar to Python, C, C, Java, JavaScript, Go, Swift,etc., but without API backward comity guarantees. There are also third- party packages for languages similar as MATLAB,C#, Julia, Scala, R/, Rust,etc.
3.Matlab:
MATLAB is a numerical computing terrain developed by MathWorks in 1984. It includes the Computer Vision Toolbox which provides colorful algorithms and functions for computer vision. These include object discovery, object shadowing, point discovery, point matching, camera estimation in 3- D, 3D reconstruction, etc. You can also produce and train custom-made object sensors in MATLAB using machine literacy algorithms similar to YOLO v2, ACF, FasterR.- CNN, etc. The MATLAB Toolbox algorithm supports law generation in C and C.
4.Cuddle:
CUDA( cipher Unified Device Architecture) is a computing platform created by Nvidia and released in 2007. It’s used by software masterminds for general purpose processing using a CUDA- enabled plates recycling unit or GPU. CUDA also has the Nvidia Performance Savages library which contains colorful functions for image, signal and videotape processing. inventors can program in different languages like C, C, Fortran, MATLAB, Python, etc. Using CUDA.
5.Simple CV:
SimpleCV is an open- source computer vision frame that can be used to make colorful computer vision operations. SimpleCV is simple( as the name suggests!) and you can use colorful advanced computer vision libraries like OpenCV without having to deeply learn all CV generalities like train formats, buffer operation, color space, eigenvalues, bit depth, matrix storehouse, bitmap storehouse, etc. SimpleCV allows you to use images or videotape aqueducts from webcams, FireWire, mobile phones, Kinects,etc. to be used in computer vision. This is the stylish frame if you need to do some quick prototyping.
6.GPU Image:
GPUImage is a frame or rather, an iOS library that allows you to apply GPU- accelerated goods and pollutants to images, live star videos and pictures. It’s based on OpenGL ES2.0. Running custom pollutants on the GPU requires a lot of law to be set up and maintained.
Computer Vision as a Service:
Microsoft Azure:
Microsoft APIs allow you to assay images, read textbook in them, and assay videotape in near-real time. You can also flag grown-up content, produce thumbnails of images, and fetch handwriting.The Google Cloud Vision API enables inventors to perform image processing by recapitulating important machine literacy models in a simple REST API that can be invoked in an operation. In addition, its Optical Character Recognition( OCR) functionality enables you to describe textbooks in your images.The Mobile Vision API lets you decry objects in prints and videos using real- time on- device vision technology. It also lets you overlook and fetch barcodes and textbooks.
Amazon Recognition:
Amazon Rekognition is a deep literacy- grounded image and videotape analysis service that makes adding an image and videotape analysis to your operations a piece of cutlet. The Service can identify objects, textbook, people, scenes and conditioning, and it also detects unhappy content, in addition to furnishing confirmation for largely accurate analysis and sentiment analysis can.
The elaboration of computer vision:
Computer vision isn’t a new technology; The first trials with computer vision began in the 1950s, and after that, it was used to autograph and interpret handwritten textbooks. At the time, computer vision analysis procedures were fairly simple, but needed a lot of work from mortal drivers, who had to manually give data samples for analysis. As you presumably guessed, it was hard to give a lot of data when doing it manually. Also, the computational power wasn’t good enough, so the error periphery was too high for this analysis.
Moment we’ve no deficit of computer power. Pall computing, coupled with robust algorithms, can help us break indeed the most complex problems. But not only is new tackle paired with sophisticated algorithms( we ’ll review them in the coming section) advancing computer vision technology; The emotional quantum of intimately available visual.
Material organization:
Computer vision systems formerly help us organize our content. Apple prints are a classic illustration. The app has access to our print collection, and it automatically adds markers to prints and allows us to browse through a more structured collection of prints. What makes Apple prints great is that the app creates a curated view of your stylish moments for you.
Recognition:
Recognition technology is used to match the filmland of people’s faces to their individualities. For illustration, Facebook is using computer vision to identify people in prints.
Augmented reality:
Computer vision is a core element of stoked reality apps. This technology helps AR apps describe physical objects( both shells and individual objects within a given physical space) in real time and use this information to place virtual objects in a physical terrain.
Computer vision exemplifications:
numerous organizations don’t have the coffers to fund computer vision labs and make deep literacy models and neural networks. They may also warrant the computing power demanded to reuse the vast set of visual data.These services give pre-built literacy models available from the pall – and also reduce the demand for calculating coffers. druggies connect to services through an operation programming interface( API) and use them to develop computer vision operations.
Then are some exemplifications of installed computer vision tasks:
Image bracket sees an image and can classify it( a canine, an apple, a person’s face). More precisely, it’s suitable to prognosticate directly whether a given image belongs to a certain class. For illustration, a social media company may want to use this to automatically identify and insulate obnoxious images uploaded by druggies.
Object discovery can use image brackets to identify a certain class of image and also describe and tabulate their presence in an image or videotape. examples include detecting damage on the assembly line or relating to ministry in need of conservation.
Object shadowing follows or tracks an object after it has been detected. This task is frequently performed in sequence or with images captured in a real- time videotape feed. Autonomous vehicles, for illustration, not only need to classify and detect objects similar to climbers, other buses and road structure, they also need to track them in stir to avoid collisions and misbehave with business laws.
Content- grounded image reclamation uses computer vision to browse, search, and recoup images from large data stores, grounded on the content of the images, rather than the metadata markers associated with them. This task can involve automatic image reflection that replaces homemade image trailing. These functions can be used for digital asset operation systems and can increase the delicacy of hunt and recoup.
Conclusion
Computer vision is a popular topic in papers about new technology. There’s a different way of using the data which makes this technology different. The vast quantities of data we produce every day, which some consider a curse to our generation, are actually used to our advantage — data can educate computers to see and understand objects.