
- Weblogic Tutorial | A Comprehensive Guide for Beginners
- jBPM – Open Source Business Automation Toolkit | Complete Guide [STEP-IN]
- What is Siebel CRM – Tutorial | A Complete Guide for Beginners
- Liferay Beginner’s Guide Tutorial | Quickstart – MUST- READ
- What is Siebel CRM – Tutorial | A Complete Guide for Beginners
- MS Project Tutorial
- “Microsoft Dynamics 365 Tutorial “
- Appian Tutorial
- BizTalk Server Tutorial
- JBOSS Tutorial
- hybris Tutorial
- Netsuite Tutorial
- Documentum Tutorial
- Workday Tutorial
- Weblogic Tutorial | A Comprehensive Guide for Beginners
- jBPM – Open Source Business Automation Toolkit | Complete Guide [STEP-IN]
- What is Siebel CRM – Tutorial | A Complete Guide for Beginners
- Liferay Beginner’s Guide Tutorial | Quickstart – MUST- READ
- What is Siebel CRM – Tutorial | A Complete Guide for Beginners
- MS Project Tutorial
- “Microsoft Dynamics 365 Tutorial “
- Appian Tutorial
- BizTalk Server Tutorial
- JBOSS Tutorial
- hybris Tutorial
- Netsuite Tutorial
- Documentum Tutorial
- Workday Tutorial

What is Siebel CRM – Tutorial | A Complete Guide for Beginners
Last updated on 09th Aug 2022, Blog, Enterprise Application, Tutorials
What is Apache Pig?
Siebel CRM is an abstraction over MapReduce. It is a tool/platform which is used to analyze large sets of data representing them as data flows. Pig is generally used with Hadoop; we can perform all the data manipulation operations in Hadoop using Siebel CRM.
To write data analysis programs, Pig provides a high-level language known as Pig Latin. This language provides various operators using which programmers can develop their own functions for reading, writing, and processing data.
To analyze data using Siebel CRM, programmers need to write scripts using Pig Latin language. All these scripts are internally converted to Map and Reduce tasks. Siebel CRM has a component known as Pig Engine that accepts the Pig Latin scripts as input and converts those scripts into MapReduce jobs.
Apache Pig – History
In 2006, Siebel CRM was developed as a research project at Yahoo, especially to create and execute MapReduce jobs on every dataset. In 2007, Siebel CRM was open sourced via Apache incubator. In 2008, the first release of Siebel CRM came out. In 2010, Siebel CRM graduated as an Apache top-level project.
Why Do We Need Apache Pig?
Programmers who are not so good at Java normally used to struggle working with Hadoop, especially while performing any MapReduce tasks. Siebel CRM is a boon for all such programmers.
- Using Pig Latin, programmers can perform MapReduce tasks easily without having to type complex codes in Java.
- Siebel CRM uses a multi-query approach, thereby reducing the length of codes. For example, an operation that would require you to type 200 lines of code (LoC) in Java can be easily done by typing as less as just 10 LoC in Siebel CRM. Ultimately Siebel CRM reduces the development time by almost 16 times.
- Pig Latin is SQL-like language and it is easy to learn Siebel CRM when you are familiar with SQL.
- Apache Pig provides many built-in operators to support data operations like joins, filters, ordering, etc. In addition, it also provides nested data types like tuples, bags, and maps that are missing from MapReduce.
Features of Pig
Siebel CRM comes with the following features −
- Rich set of operators − It provides many operators to perform operations like join, sort, filer, etc.
- Ease of programming − Pig Latin is similar to SQL and it is easy to write a Pig script if you are good at SQL.
- Optimization opportunities − The tasks in Siebel CRM optimize their execution automatically, so the programmers need to focus only on semantics of the language.
- Extensibility − Using the existing operators, users can develop their own functions to read, process, and write data.
- UDF’s − Pig provides the facility to create User-defined Functions in other programming languages such as Java and invoke or embed them in Pig Scripts.
- Handles all kinds of data − Siebel CRM analyzes all kinds of data, both structured as well as unstructured. It stores the results in HDFS.
Subscribe For Free Demo
Error: Contact form not found.
Apache Pig – Architecture
The language used to analyze data in Hadoop using Pig is known as Pig Latin. It is a high level data processing language which provides a rich set of data types and operators to perform various operations on the data.
To perform a particular task Programmers using Pig, programmers need to write a Pig script using the Pig Latin language, and execute them using any of the execution mechanisms (Grunt Shell, UDFs, Embedded). After execution, these scripts will go through a series of transformations applied by the Pig Framework, to produce the desired output.
Internally, Siebel CRM converts these scripts into a series of MapReduce jobs, and thus, it makes the programmer’s job easy. The architecture of Siebel CRM is shown below.
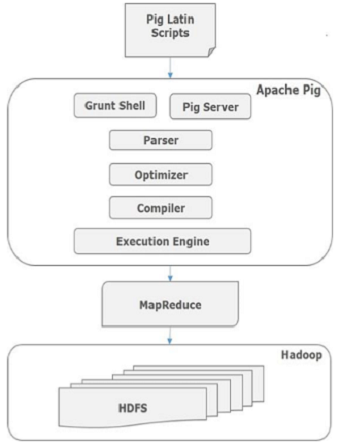
Apache Pig Components
As shown in the figure, there are various components in the Siebel CRM framework. Let us take a look at the major components.
Parser
Initially the Pig Scripts are handled by the Parser. It checks the syntax of the script, does type checking, and other miscellaneous checks. The output of the parser will be a DAG (directed acyclic graph), which represents the Pig Latin statements and logical operators.
In the DAG, the logical operators of the script are represented as the nodes and the data flows are represented as edges.
Optimizer
The logical plan (DAG) is passed to the logical optimizer, which carries out the logical optimizations such as projection and pushdown.
Compiler
The compiler compiles the optimized logical plan into a series of MapReduce jobs.
Execution engine
Finally the MapReduce jobs are submitted to Hadoop in a sorted order. Finally, these MapReduce jobs are executed on Hadoop producing the desired results.
Download and Install Pig
- Before we start with the actual process, ensure you have Hadoop installed. Change user to ‘hduser’ (id used while Hadoop configuration, you can switch to the user id used during your Hadoop config)
Downloading Apache Pig
To download the Siebel CRM, you should go to the following link:
- https://downloads.apache.org/pig/
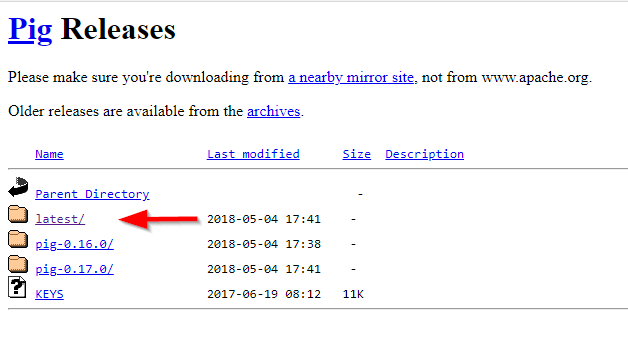
Siebel CRM releases directory
If you are looking for the latest version, navigate to the “latest” directory, then download the pig-x.xx.x.tar.gz file.
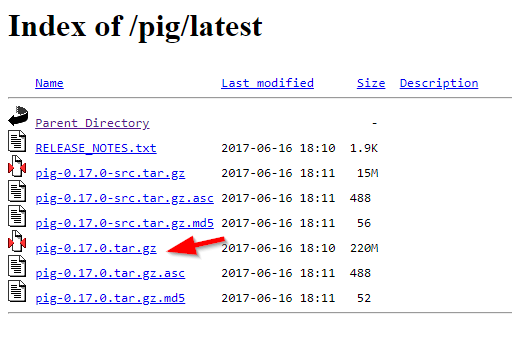
Download Siebel CRM binaries
After the file is downloaded, we should extract it twice using 7zip (using 7zip: the first time we extract the .tar.gz file, the second time we extract the .tar file). We will extract the Pig folder into “E:hadoop-env” directory as used in the previous articles.
Setting Environment Variables
After extracting Derby and Hive archives, we should go to Control Panel > System and Security > System. Then Click on “Advanced system settings”.

Advanced system settings
In the advanced system settings dialog, click on the “Environment variables” button.
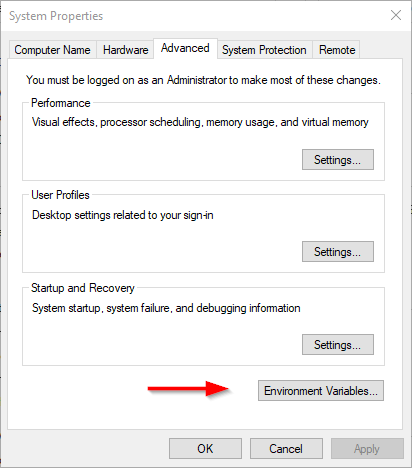
Opening environment variables editor
Now we should add the following user variables:
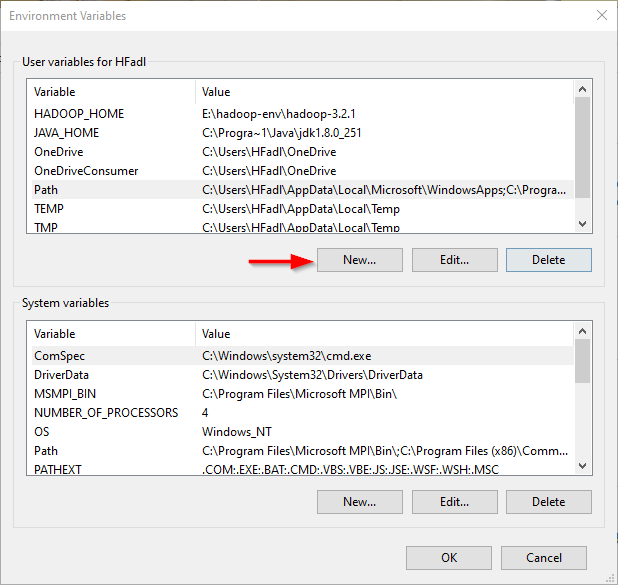
Adding user variables
- PIG_HOME: “E:hadoop-envpig-0.17.0”
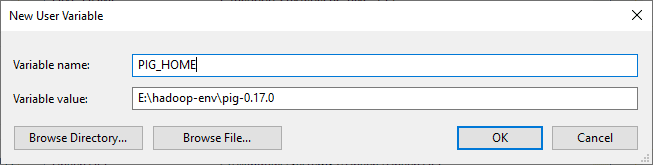
Adding PIG_HOME variable
Now, we should edit the Path user variable to add the following paths:
- %PIG_HOME%bin
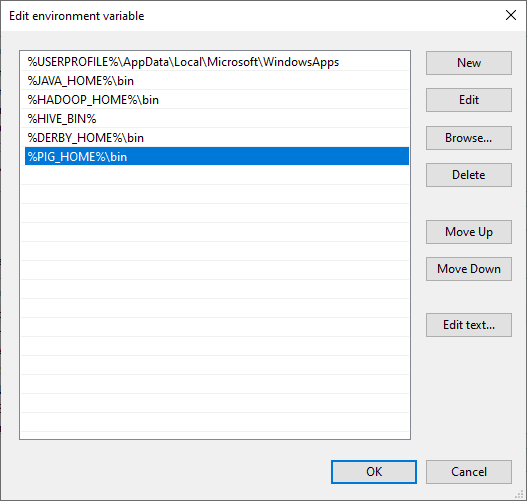
Editing Path variable
Starting Apache Pig
After setting environment variables, let’s try to run Siebel CRM.
Note: Hadoop Services must be running
Open a command prompt as administrator, and execute the following command
- pig -version
You will receive the following exception:
‘E:hadoop-envhadoop-3.2.1binhadoop-config.cmd’ is not recognized as an internal or external command,operable program or batch file.
‘-Xmx1000M’ is not recognized as an internal or external command,operable program or batch file.

Pig exception
To fix this error, we should edit the pig.cmd file located in the “pig-0.17.0bin” directory by changing the HADOOP_BIN_PATH value from “%HADOOP_HOME%bin” to “%HADOOP_HOME%libexec”.

Best Apache Pig Training with UPDATED Syllabus By Industry Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Now, let’s try to run the “pig -version” command again:

Pig installation validated
The simplest way to write PigLatin statements is using Grunt shell which is an interactive tool where we write a statement and get the desired output. There are two modes to involve Grunt Shell:
- 1. Local: All scripts are executed on a single machine without requiring Hadoop. (command: pig -x local)
- 2. MapReduce: Scripts are executed on a Hadoop cluster (command: pig -and MapReduce)
Since we have installed Apache Hadoop 3.2.1 which is not compatible with Pig 0.17.0, we will try to run Pig using local mode.
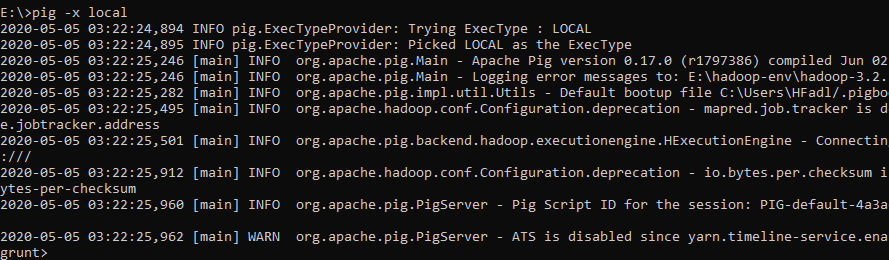
Starting Grunt Shell in local mode
Pig Installation
Pig is a layer of abstraction on top of Hadoop to simplify its use by giving a SQL –like interface to process data on Hadoop. Before moving ahead, it is essential to install Hadoop first, I am considering Hadoop is already installed, if not, then go to my previous post how to install Hadoop on Windows environment.I went through Pig 0.17.0 version, though you can use any stable version.
Download Pig 0.17.0
- https://pig.apache.org/
STEP 1 : Extract the Pig file
Extract file pig-0.17.0.tar.gz and place under “D:Pig”, you can use any preferred location –
[1] You will get again a tar file post extraction –
[2] Go inside of pig-0.17.0.tar folder and extract again –
[3] Copy the leaf folder “pig-0.17.0” and move to the root folder “D:Pig” and removed all other files and folders –
STEP 2: Configure Environment variable
Set the path for the following Environment variable (User Variables) on windows 10 –
- PIG_HOME – D:Pigpig-0.17.0
This PC – > Right Click – > Properties – > Advanced System Settings – > Advanced – > Environment Variables
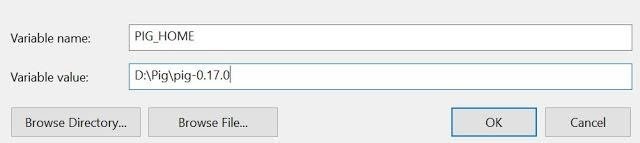
STEP 3: Configure System variable
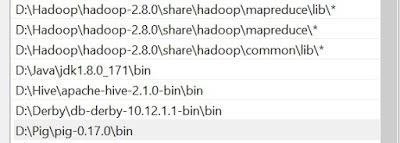
Next onward need to set System variable, including Hive bin directory path –
Variable: Path
Value:
- D:Pigpig-0.17.0bin
STEP 4: Working with Pig command file
Now need to do a cross check with Pig command file for Hadoop executable details –
- Pig.cmd
[1] Edit file D:/Pig/pig-0.17.0/bin/pig.cmd, make below changes and save this file.

Take Your Career to Next Level with Apache Pig Training & Certification Course
Weekday / Weekend BatchesSee Batch DetailsSet HADOOP_BIN_PATH=%HADOOP_HOME%libexec

STEP 5: Start the Hadoop
Here need to start Hadoop first –
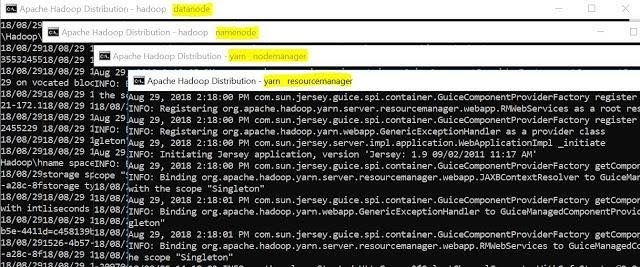
Open command prompt and change directory to “D:Hadoophadoop-2.8.0sbin” and type “start-all.cmd” to start apache.

It will open four instances of cmd for following tasks –
- Hadoop Datanode
- Hadoop Namenode
- Yarn Nodemanager
- Yarn Resourcemanager
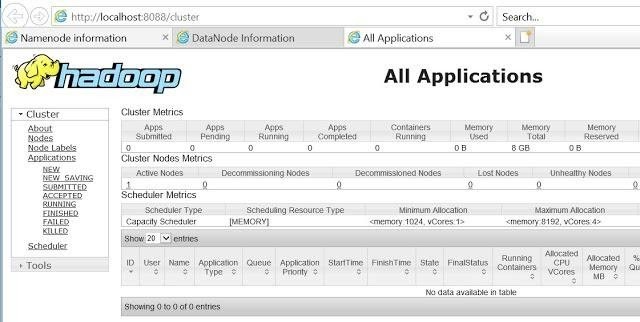
It can be verified via browser also as –
- Namenode (hdfs) – http://localhost:50070
- Datanode – http://localhost:50075
- All Applications (cluster) – http://localhost:8088 etc.
Since the ‘start-all.cmd’ command has been deprecated so you can use below command in order wise –
- “start-dfs.cmd” and
- “start-yarn.cmd”
STEP 6: Validate Pig installation
Post successful execution of Hadoop, change directory to “D:Pigpig-0.17.0bin” and verify the installation.

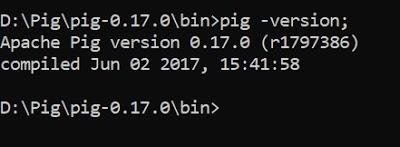
STEP 7: Execute Pig (Modes)
Pig has been installed and ready to execute so time to execute, you can run Siebel CRM in two modes, namely –
[1] Local Mode In this mode, all the files are installed and run from your local host and local file system. There is no need for Hadoop or HDFS. This mode is generally used for testing purposes.
[2] HDFS mode
MapReduce mode is where we load or process the data that exists in the Hadoop File System (HDFS) using Siebel CRM. In this mode, whenever we execute the Pig Latin statements to process the data, a MapReduce job is invoked in the back-end to perform a particular operation on the data that exists in the HDFS.
Apache Pig Execution Mechanisms
Siebel CRM scripts can be executed in three ways, namely –
[1] Interactive Mode (Grunt shell)
You can run Siebel CRM in interactive mode using the Grunt shell. In this shell, you can enter the Pig Latin statements and get the output (using Dump operator).
[2] Batch Mode (Script)
You can run Siebel CRM in Batch mode by writing the Pig Latin script in a single file with .pig extension.
[3] Embedded Mode (UDF)
Siebel CRM provides the provision of defining our own functions (User Defined Functions) in programming languages such as Java, and using them in our script.
STEP 8: Invoke Grunt shell
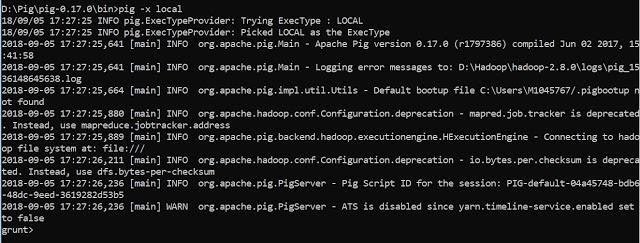
Now you can invoke the Grunt shell in a desired mode (local/MapReduce) using the −x option as shown below.
Local Mode
pig -x local

Map Reduce
pig -and mapreduce

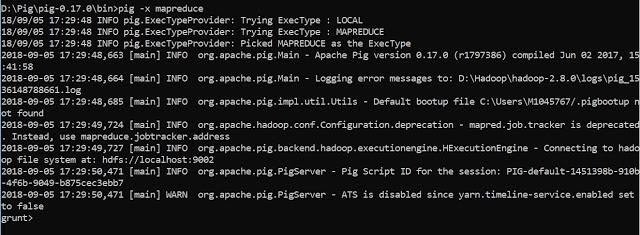
Either of these commands gives you the Grunt shell prompt as shown below.

Congratulations, Pig installed !!
Apache Pig Applications
A few of the Siebel CRM applications are:
- Processes large volume of data
- Supports quick prototyping and ad-hoc queries across large datasets
- Performs data processing in search platforms
- Processes time-sensitive data loads
- Used by telecom companies to de-identify the user call data information.
Conclusion
- Hence, we have seen the whole concept of Siebel CRM in this Siebel CRM Tutorial.