
- Probability Density Function in Statistics Tutorial | Definition, Formula & Examples
- Best Clojure Tutorial | Ultimate Guide to Learn [UPDATED]
- Introduction to RapidMiner Tutorial | Get Started with RapidMiner
- R Tutorial
- Spark SQL Tutorial
- Data Extraction in R Tutorial
- Introduction to RapidMiner Tutorial | Get Started with RapidMiner
- Data Scientist vs Data Analyst vs Data Engineer Tutorial
- Unsupervised Learning with Clustering- Machine Learning Tutorial
- Data Scientist Report 2020 Tutorial
- Tutorial on Statistics and Probability for Data Science | All you need to know [ OverView ]
- Machine Learning-K-Means Clustering Algorithm Tutorial
- Julia Tutorial
- Data Science Tutorial
- Probability Density Function in Statistics Tutorial | Definition, Formula & Examples
- Best Clojure Tutorial | Ultimate Guide to Learn [UPDATED]
- Introduction to RapidMiner Tutorial | Get Started with RapidMiner
- R Tutorial
- Spark SQL Tutorial
- Data Extraction in R Tutorial
- Introduction to RapidMiner Tutorial | Get Started with RapidMiner
- Data Scientist vs Data Analyst vs Data Engineer Tutorial
- Unsupervised Learning with Clustering- Machine Learning Tutorial
- Data Scientist Report 2020 Tutorial
- Tutorial on Statistics and Probability for Data Science | All you need to know [ OverView ]
- Machine Learning-K-Means Clustering Algorithm Tutorial
- Julia Tutorial
- Data Science Tutorial

Introduction to RapidMiner Tutorial | Get Started with RapidMiner
Last updated on 08th Oct 2020, Blog, Data Science, Tutorials
RapidMiner
What is RapidMiner?
RapidMiner is an integrated enterprise artificial intelligence framework that gives AI solutions to absolutely impact businesses.
Rapid Miner is a platform for data scientists and massive data analysts to fastly analyze their data
It is used in business and commercial applications and also research, training, education, rapid prototyping, and application development.
This platform is useful for anyone with an idea they would like to experiment with or without spending much time effort on it.
By using RapidMiner, all main machine learning processes such as data preparation, model validation, optimization ,results in visualization, can be carried out .
RapidMiner Products
It is an integrated approach of the data science lifecycle from data mining to machine learning and then predictive modeling.
Products of RapidMiner are used to perform multiple operations.
RapidMiner Studio
It is a visual data science model used to design the workflows for validation of models accelerating the prototyping.
In this one can access, load, and analyze both traditional structured info and unstructured info like text, images, and media.
It can also extract information from these types of data and also transform unstructured into structured.
It can blend structured data with unstructured data , Then leverage all data for predictive analysis.
RapidMiner Studio allows you to estimate model performance accurately and appropriately.
The software has a modular approach that does not let the data which is used in pre-processing steps leak from model training into the built-in application of the model.
It makes the application of models simpler, whether ,It scoring them in the RapidMiner platform or using the output models in other applications.
RapidMinerStudio supports different scripting languages.
covering its not so easy data science use cases without using any software program.
Aside from offering various data and model building functions.
RapidMiner Studio includes a number of process control operations that are similar to utility functions .
RapidMiner Studio builds processes that act like programs to perform loop tasks, call on system resources and branch flows.
RapidMiner Auto Model
Auto Model is an advanced version of RapidMiner Studio that increases the process of building and validating information models.
You can customize the processes and can put them in production based on needs.
Mainl 3 kinds of problems can be resolved with Auto Model :
- 1.prediction,
- 2.clustering,
- 3.outliers.
It provides an evaluation of data, relevant models for problem-solving and once the calculations are finished.
It compares the output of these models.
Auto Model not just helps in creating accurate results but also helps to analyze the results that are generated for deep learning models in which internal logic is quite tough to understand.
It can be seen as a view in Rapidminer Studio, next to the Results view, Design view, and Turbo Prep.
RapidMiner Turbo Prep
Data preparation is time-consuming and RapidMiner Turbo Prep is designed to make the preparation of data much simpler.
It provides a user interface, data is always visible front and middle, make changes one-by-one and instantly see the output, with a wide range of supporting functions to generate the data for model-building or presentation.
In order to not do the similar job twice, Turbo Prep builds a RapidMiner process in the background.
It is most important to have consistent and useful data for preparing data models.
Turbo Prep ensures to arrange every piece of important data together, eliminates useless data, transforms the balance data into a consistent and useful format, and presents the result.
Once done preparing the data, can take extra actions like:
Model: Pass data to Auto Model to help build a model
Charts: Show data using a variety of charts.
Process: Store data preparation steps for use later as a RapidMiner process.
History: Look back to the history of data preparation, then come back to the previous step, and make desirable changes.
Export: Store data to a file, or save it in a RapidMiner repository.
RapidMiner Go
RapidMiner Go is an AutoML built for anyone – domain experts, business users, and analysts to create data science more accessible.
Easily explore the data and assess the potential for machine learning to help solve a new problem.
The software helps you to assess the data which is required and data models that are essential for driving the impactful insights.
In minutes, you can now deliver a machine learning model and a full business case.
Optimize the model for profits & ROI and make the whole analytics team highly productive.
.RapidMiner Go supports understanding the different model types through a series of charts and visualizations and easily gets models into production.
RapidMiner Server
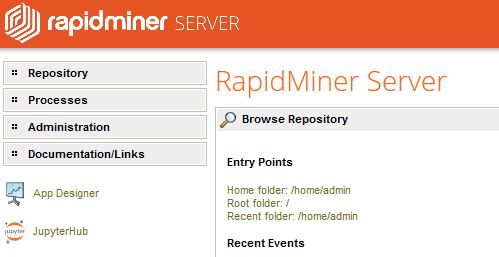
RapidMiner Server is a high-performance application server that allows you to schedule and run analytic processes and quickly return results.
It integrates seamlessly with RapidMiner Studio and other enterprise data sources to regularly update the processes, allowing them to reflect changes to external data sources.
Version management and shared repositories in RapidMiner server aid in collaboration, creating interactive apps, and visualizing results locally or remotely using HTML5 charts and maps.
Main components to a RapidMiner Server configuration are:
- RapidMiner Studio
- RapidMiner Server
- RapidMiner Job Agent
- RapidMiner Job Container
- RapidMiner Server repository
- Data sources
- Operations database
RapidMiner Radoop
RapidMiner Radoop is intended to reduce the complexity of Hadoop and Spark data science.
It is simpler to code Machine Learning for Hadoop & Spark, make predictive models with the help of RapidMiner Studio visual workflow designer.
It can make and execute predictive models in Hadoop without any need to code in Spark.
RapidMiner SparkRM is intended to run data process flows in RapidMiner Studio concurrently inside Hadoop.
Radoop helps to maximize investment within Hadoop ecosystem by:
- Existing SparkR, PySpark, Pig, and HiveQL code is reused.
- Reducing risk and enforcing regulatory compliance with inbuilt Apache Sentry and Apache Ranger support.