
- Difference between Data Lake vs Data Warehouse: A Complete Guide For Beginners with Best Practices
- What is Data Mining?| All you need to know [ OverView ]
- What is Data Mining and Data Warehousing?
- Clustering in SSIS | A Definitive Guide with Best Practices [ OverView ]
- What is Data Mart in Data Warehouse? :A Definitive Guide with Best Practices & REAL-TIME Examples
- Accessing Heterogeneous Data In SSIS | Step-By-Step Process with REAL-TIME Examples
- How to Use Java Classes In Talend ? : Step-By-Step Process with REAL-TIME Examples
- What is ODI? ( Oracle Data Integrator ) – A Complete Beginners Guide
- What is Logging in SSIS ( SQL Server Integration Services ) | A Complete Guide with Best Practices
- Applications of Data Mining Free Guide Tutorial & REAL-TIME Examples
- Informatica ETL Tools | Free Guide Tutorial & REAL-TIME Examples
- What Is Data Mining ? – Everything You Need to Know
- What is Amazon Redshift?
- What is Informatica PowerCenter?
- Difference between Data Lake vs Data Warehouse: A Complete Guide For Beginners with Best Practices
- What is Data Mining?| All you need to know [ OverView ]
- What is Data Mining and Data Warehousing?
- Clustering in SSIS | A Definitive Guide with Best Practices [ OverView ]
- What is Data Mart in Data Warehouse? :A Definitive Guide with Best Practices & REAL-TIME Examples
- Accessing Heterogeneous Data In SSIS | Step-By-Step Process with REAL-TIME Examples
- How to Use Java Classes In Talend ? : Step-By-Step Process with REAL-TIME Examples
- What is ODI? ( Oracle Data Integrator ) – A Complete Beginners Guide
- What is Logging in SSIS ( SQL Server Integration Services ) | A Complete Guide with Best Practices
- Applications of Data Mining Free Guide Tutorial & REAL-TIME Examples
- Informatica ETL Tools | Free Guide Tutorial & REAL-TIME Examples
- What Is Data Mining ? – Everything You Need to Know
- What is Amazon Redshift?
- What is Informatica PowerCenter?

Accessing Heterogeneous Data In SSIS | Step-By-Step Process with REAL-TIME Examples
Last updated on 04th Nov 2022, Artciles, Blog, Datawarehouse
- In this article you will learn:
- 1.Introduction.
- 2.What are the heterogeneous data sources?
- 3.Data Extraction.
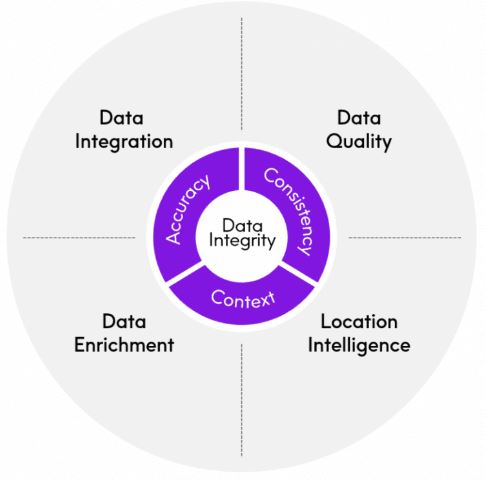
- 4.Data Integrity.
- 5.Scalability.
- 6.Conclusion.
Introduction:
- Consolidating a data from disparate structured, unstructured, and semi-structured sources can be a complex. A survey conducted by Gartner revealed that are one-third of respondents consider “integrating a multiple data sources” as one of top four integration challenges.
- Understanding a common problems faced during this process can help enterprises successfully counteract them. Here are three challenges generally faced by an organizations when integrating heterogeneous data sources as well as ways to be resolve them.
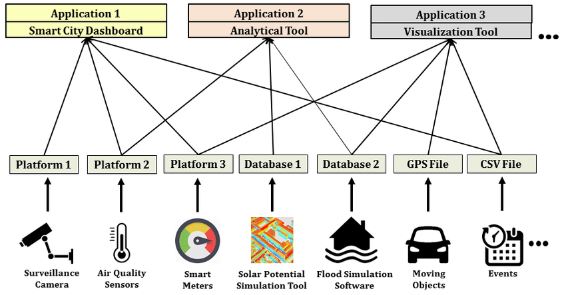
What are heterogeneous data sources?
Heterogeneous data are any data with more variability of data types and formats. They are possibly ambiguous and a low quality due to missing values, high data redundancy, and also untruthfulness. It is complex to integrate heterogeneous data to meet abusiness information demands.
Data Extraction:
Challenge:
- Pulling a source data is the first step in an integration process. But it can be complicated and a time-consuming if data sources have various formats, structures, and types. Moreover, once the data is an extracted, it needs to be transformed to made it compatible with the destination system before an integration.
Solution:
- The best way to go about this is to create the list of sources that organization deals with regularly. Look for integration tool that supports extraction from all sources. Preferably, go with tool that supports a structured, unstructured, and semi-structured sources to simplify and streamline an extraction process.
Data Integrity:
Challenge:
- Data Quality is the primary concern in every data integration strategy. A Poor data quality can be a compounding problem that can affect an entire integration cycle. Processing a invalid or incorrect data can lead to be faulty analytics, which if passed downstream, can be corrupt results.
Solution:
- To ensure that a correct and accurate data goes into a data pipeline, create a data quality management plan before starting project. Outlining these steps guarantees that are bad data is kept out of each step of the data pipeline, from a development to processing.
Scalability:
Challenge:
- Data heterogeneity leads to be inflow of data from a diverse sources into a unified system, which can ultimately lead to an exponential growth in a data volume. To tackle this challenge, an organizations need to employ robust integration solution that has features to handle more volume and disparity in a data without compromising on performance.
Solution:
- Anticipating an extent of growth in an enterprise data can help organizations select a right integration solution that meets their scalability and diversity requirements. Integrating one data point at a time is a beneficial in this scenario. Evaluating a value of each data point with respect to overall integration strategy can help to prioritize and plan.
Say that an enterprise need to consolidate data from a three different sources: Salesforce, SQL Server, and also Excel files. The data within every system can be categorized into be unique datasets, such as sales, customer information, and financial data. Prioritizing and integrating these datasets one at time can help an organizations gradually scale data processes.Conquering challenges of a heterogeneous data integration is crucialto enterprise success. Have an encountered a any problems when integrating data from a disparate sources? Were are able to resolve them?There are following types of a data heterogeneity 2:
- Syntactic heterogeneity occurs when a two data sources are not an expressed in a same language.
- Conceptual heterogeneity, also known as a semantic heterogeneity or a logical mismatch, denotes a differences in modelling a same domain of interest.
- Terminological heterogeneity stands for the variations in names when referring to a same entities from various data sources.
- Semiotic heterogeneity, also known as a pragmatic heterogeneity, stands for various interpretation of an entities by people.
- Data representation can be explained at four levels . Level 1 is diverse raw data with a various types and from different sources.
Level 2 is called ‘unified representation’. Heterogeneous data require to be unified. Also, too much data can lead to more cognitive and data processing costs.
- This layer converts an individual attributes into the information in terms of ‘what-when-where’. Level 3 is aggregation. Spatial data can be naturally represented in a form of spatial grids with thematic attributes.
- Processing an operators are segmentation and aggregation, etc. Aggregation aids simple visualization and provides a intuitive query.
- The situation at a location is be characterized based on spatiotemporal descriptors are determined by using appropriate operators at a level 3. The final step in situation detection is the classification operation that uses a domain knowledge to assign an appropriate class to every cell.
- Metadata are the crucial for a future querying.
- For relational tables and some Extensible Markup Language (XML) documents,can explicit schema definitions in a Structured Query Language (SQL), XML Schema Definition (XSD), or a Document Type Definition (DTD) can be directly obtained from the sources and integrated into metamodel. The XML technique is used for a data translation.
- The tricky part is semi-structured data which contain a implicit schemas. Therefore,a component Structural Metadata Discovery (SMD) takes over responsibility of discovering implicit a metadata from a semi-structured data Metadata management problems are important.
- For an appropriate interpretation of a heterogeneous big data, detailed metadata are needed Some reports contain a some metadata, but many more details are about the specific sensor used in a data collection are needed for the research purposes.
- The collection of a metadata and data provenance is a major challenge when a data are collected under a duress and stressful situations .
- The challenges of a Big Data algorithms are concentrate on algorithm design in tackling a difficulties raised by a big data volumes, distributed data distributions, and complex and a dynamic data characteristics.
The challenges are include the following stages:
First, heterogeneous, incomplete, uncertain, sparse, and a multi-source data are pre-processed by a data fusion techniques. A Second, dynamic and complex data are mined after a pre-processing.Third, a global knowledge obtained by the local learning and model fusion is tested and relevant information is fed back to pre-processing stage. Then the model and parameters are adjusted according to feedback.In a whole process, information sharing is not only promise of smooth development of every stage, but also a purpose of a big data processing 7.This paper focuses on a four aspects:
1) introduces a data processing methods including a data cleaning, data integration, and dimension reduction and also data normalization for heterogeneous data and Big Data analytics.
2) presents a big data concepts, Big Data analytics, and Big Data tools.
3) compares a traditional DM/ML methods with a deep learning, especially their feasibility in a Big Data analytics.
4) discusses the potential of a confluences among a Big Data analytics, deep learning, HPC, and also heterogeneous computing.
Conclusion:
It is important to develop an efficient big data cleansing approaches to be improve data quality.Data Virtualization and also Data lakes are powerful approaches that are help data integration.PCA and EFA are often used to perform a data dimension reduction.Heterogeneity of big data also means a dealing with structured, semi-structured, and unstructured data simultaneously. There are the challenge in every phase of Big Data analytics.These include a real-time processing, handling complex data types, and a concurrent data processing.