
- Difference between Artificial Intelligence and Machine Learning | Everything You Need to Know
- How Quantum Computing Will Transform Cybersecurity | All you need to know [ OverView ]
- What is Design Thinking? : 5 Stages in the Design Thinking Process [OverView]
- What is Design Thinking Model?
- The Top 5 Technology Trend Creators | All you need to know [ OverView ]
- AI vs Data Science: Mapping Your Career Path [ Job & Future ]
- What is Computer Vision & How does it Works ? : Everything You Need to Know [ OverView ]
- What is TensorFlow? : Expert’s Top Picks | Everything You Need to Know
- Keras vs Tensorflow vs Pytorch | Difference You Should Know
- Advantages and Disadvantages of Artificial Intelligence
- What are the Deep Learning Algorithms You Should Know About?
- The Rise of Artificial Intelligence and Machine Learning Job Trends
- Top 5 Jobs In AI and Key Skills Needed To Help You Land One
- Top AI and Machine Learning Trends for 2020
- How to Build a Career in AI and Machine Learning?
- Artificial Intelligence for Beginners
- What Is Emotional Intelligence and Its Importance?
- What Is Artificial Neural Networks?
- Top Real World Artificial Intelligence Applications
- What is Artificial Intelligence?
- Difference between Artificial Intelligence and Machine Learning | Everything You Need to Know
- How Quantum Computing Will Transform Cybersecurity | All you need to know [ OverView ]
- What is Design Thinking? : 5 Stages in the Design Thinking Process [OverView]
- What is Design Thinking Model?
- The Top 5 Technology Trend Creators | All you need to know [ OverView ]
- AI vs Data Science: Mapping Your Career Path [ Job & Future ]
- What is Computer Vision & How does it Works ? : Everything You Need to Know [ OverView ]
- What is TensorFlow? : Expert’s Top Picks | Everything You Need to Know
- Keras vs Tensorflow vs Pytorch | Difference You Should Know
- Advantages and Disadvantages of Artificial Intelligence
- What are the Deep Learning Algorithms You Should Know About?
- The Rise of Artificial Intelligence and Machine Learning Job Trends
- Top 5 Jobs In AI and Key Skills Needed To Help You Land One
- Top AI and Machine Learning Trends for 2020
- How to Build a Career in AI and Machine Learning?
- Artificial Intelligence for Beginners
- What Is Emotional Intelligence and Its Importance?
- What Is Artificial Neural Networks?
- Top Real World Artificial Intelligence Applications
- What is Artificial Intelligence?

What are the Deep Learning Algorithms You Should Know About?
Last updated on 14th Oct 2020, Artciles, Artificial Intelligence, Blog
Deep Learning algorithms you should know
- Now let’s talk about more complex things. Deep learning algorithms, or put it differently, mechanisms that allow us to use this cutting-edge technology:
Backpropagation
- The backpropagation algorithm is a popular supervised algorithm for training feedforward neural networks for supervised learning.
- Essentially, backpropagation evaluates the expression for the derivative of the cost function as a product of derivatives between each layer from left to right — “backwards” — with the gradient of the weights between each layer being a simple modification of the partial products (the “backwards propagated error”).
- We feed the network with data, it produces an output, we compare that output with a desired one (using a loss function) and we readjust the weights based on the difference. And repeat. And repeat.
- The adjustment of weights is performed using a non-linear optimization technique called stochastic gradient descent.
- Let’s say that for some reason we want to identify images with a tree. We feed the network with any kind of images and it produces an output. Since we know if the image has actually a tree or not, we can compare the output with our truth and adjust the network.
- As we pass more and more images, the network will make fewer and fewer mistakes. Now we can feed it with an unknown image, and it will tell us if the image contains a tree. Pretty cool, right?
Subscribe For Free Demo
Error: Contact form not found.
Feedforward Neural Networks (FNN)
- Feedforward Neural Networks are usually fully connected, which means that every neuron in a layer is connected with all the other neurons in the next layers. The described structure is called Multilayer Perceptron and originated back in 1958.
- Single-layer perceptrons can only learn linearly separable patterns, but a multilayer perceptron is able to learn non-linear relationships between the data.
- The goal of a feedforward network is to approximate some function f. ??? ???????, ??? ? ??????fi??, ? = ?(x) maps an input x to a category y.
- A feedforward network defines a mapping y = f(x;θ) and learns the value of the parameters θ that result in the best function approximation.
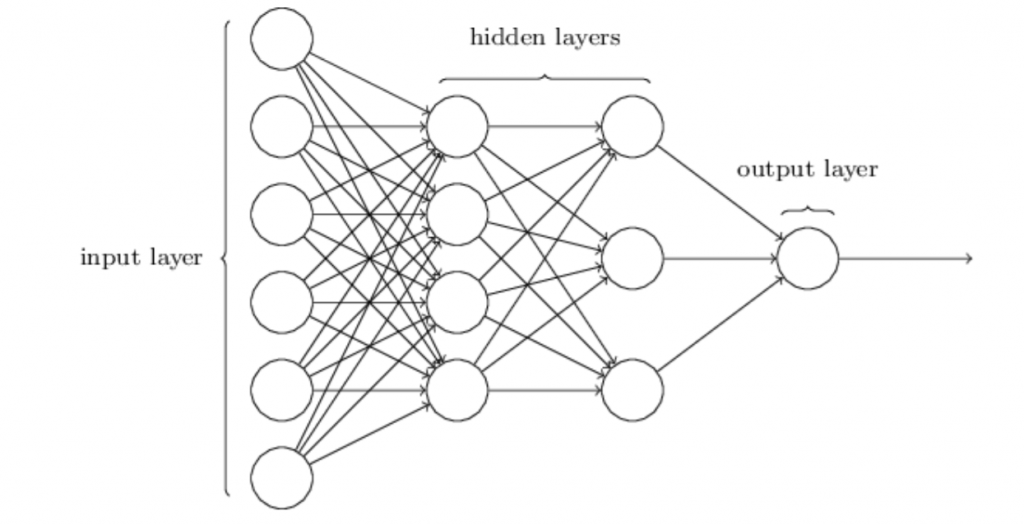
- These models are called feedforward because information flows through the function being evaluated from x, through the intermediate computations used to define f, and finally to the output y.
- There are no feedback connections in which outputs of the model are fed back into itself. When feedforward neural networks are extended to include feedback connections, they are called recurrent neural networks.
Convolutional Neural Networks (CNN)
- ConvNets have been successful in identifying faces, objects, and traffic signs apart from powering vision in robots and self-driving cars.
- From the Latin convolvere, “to convolve” means to roll together. For mathematical purposes, convolution is the integral measuring of how much two functions overlap as one passes over the other.
- Think of convolution as a way of mixing two functions by multiplying them.
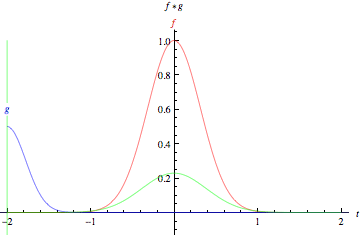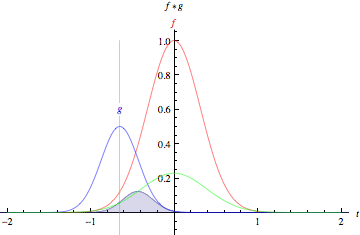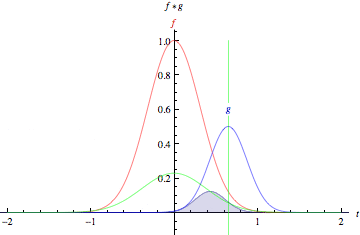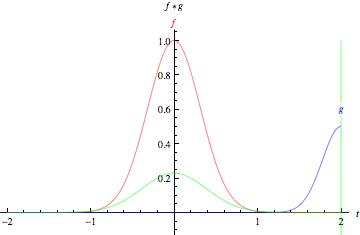
- The green curve shows the convolution of the blue and red curves as a function of t, the position indicated by the vertical green line. The gray region indicates the product g(tau)f(t-tau) as a function of t, so its area as a function of t is precisely the convolution.”
- The product of those two functions’ overlap at each point along the x-axis is their convolution. So in a sense, the two functions are being “rolled together.”
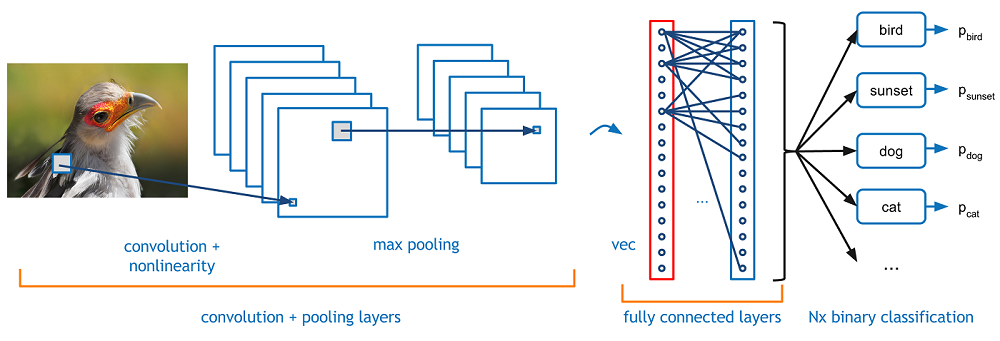
- In a way, they try to regularize feedforward networks to avoid overfitting (when the model learns only pre-seen data and can’t generalize), which makes them very good in identifying spatial relationships between the data.
- Another great article I will certainly recommend — The best explanation of Convolutional Neural Networks on the Internet!

Learn Practical Oriented Deep Learning Course with Certifications By Real Time Experts
Weekday / Weekend BatchesSee Batch DetailsRecurrent Neural Networks (RNN)
- Recursive neural networks are very successful in many NLP tasks. The idea of RNN is to consistently use information. In traditional neural networks, it is understood that all inputs and outputs are independent.
- But for many tasks this is not suitable. If you want to predict the next word in a sentence, it is better to consider the words preceding it.
- RNNs are called recurrent because they perform the same task for each element of the sequence, and the output depends on previous calculations.
- Another interpretation of RNN: these are networks that have a “memory” that takes into account prior information.
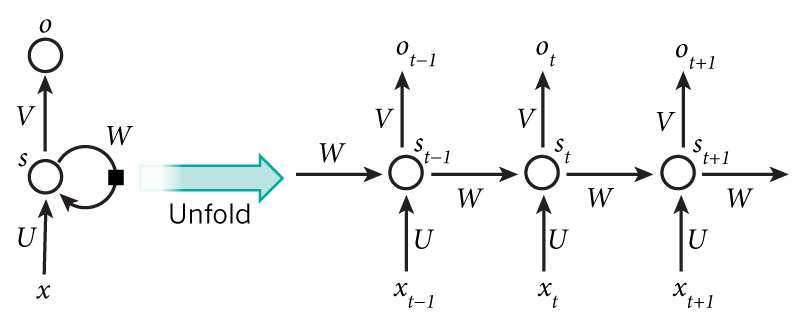
- The diagram above shows that the RNN is deployed to a complete network. By sweep, we simply write out the network for complete consistency.
- For example, if the sequence is a sentence of 5 words, the sweep will consist of 5 layers, a layer for each word.
The formulas that define the calculations in RNN are as follows:
- x_t — input at time step t. For example, x_1 may be a one-hot vector corresponding to the second word of a sentence.
- s_t is the hidden state in step t. This is the “memory” of the network. s_t depends, as a function, on previous states and the current input x_t: s_t = f (Ux_t + Ws_ {t-1}). The function f is usually non-linear, for example tanh or ReLU. s _ {- 1}, which is required to compute the first hidden state, is usually initialized to zero (zero vector).
- o_t — exit at step t. For example, if we want to predict a word in a sentence, the output may be a probability vector in our dictionary. o_t = softmax (Vs_t)
Deep Learning Sample Resumes! Download & Edit, Get Noticed by Top Employers!
Download
Recursive Neural Network
- Recursive Neural Networks are another form of recurrent networks with the difference that they are structured in a tree-like form. As a result, they can model hierarchical structures in the training dataset.
- They are traditionally used in NLP in applications such as Audio to text transcription and sentiment analysis because of their ties to binary trees, contexts, and natural-language-based parsers.
- However, they tend to be much slower than Recurrent Networks