
- 10 Best Data Analytics Tools for Big Data Analysis | Everything You Need to Know
- What is Azure Databricks | A Complete Guide with Best Practices
- Elasticsearch Nested Mapping : The Ultimate Guide with Expert’s Top Picks
- Various Talend Products and their Features | Expert’s Top Picks with REAL-TIME Examples
- What is Apache Pig ? : A Definitive Guide | Everything You Need to Know [ OverView ]
- Introduction to HBase and Its Architecture | A Complete Guide For Beginners
- What is Azure Data Lake ? : Expert’s Top Picks | Everything You Need to Know
- What is Splunk Rex : Step-By-Step Process with REAL-TIME Examples
- What is Data Pipelining? : Step-By-Step Process with REAL-TIME Examples
- Dedup : Splunk Documentation | Step-By-Step Process | Expert’s Top Picks
- What Is a Hadoop Cluster? : A Complete Guide with REAL-TIME Examples
- Spark vs MapReduce | Differences and Which Should You Learn? [ OverView ]
- Top Big Data Challenges With Solutions : A Complete Guide with Best Practices
- Hive vs Impala | What to learn and Why? : All you need to know
- What is Apache Zookeeper? | Expert’s Top Picks | Free Guide Tutorial
- What is HDFS? Hadoop Distributed File System | A Complete Guide [ OverView ]
- Who Is a Data Architect? How to Become and a Data Architect? : Job Description and Required Skills
- Kafka vs RabbitMQ | Differences and Which Should You Learn?
- What is Apache Hadoop YARN? Expert’s Top Picks
- How to install Apache Spark on Windows? : Step-By-Step Process
- What is Big Data Analytics ? Step-By-Step Process
- Top Big Data Certifications for 2020
- What is Hive?
- Big Data Engineer Salary
- How Facebook is Using Big Data?
- Top Influencers in Big Data and Analytics in 2020
- How to Become a Big Data Hadoop Architect?
- What Are the Skills Needed to Learn Hadoop?
- How to Become a Big Data Analyst?
- How Big Data Can Help You Do Wonders In Your Business
- Essential Concepts of Big Data and Hadoop
- How Big Data is Transforming Retail Industry?
- How big Is Big Data?
- How to Become a Hadoop Developer?
- Hadoop Vs Apache Spark
- PySpark Programming
- 10 Best Data Analytics Tools for Big Data Analysis | Everything You Need to Know
- What is Azure Databricks | A Complete Guide with Best Practices
- Elasticsearch Nested Mapping : The Ultimate Guide with Expert’s Top Picks
- Various Talend Products and their Features | Expert’s Top Picks with REAL-TIME Examples
- What is Apache Pig ? : A Definitive Guide | Everything You Need to Know [ OverView ]
- Introduction to HBase and Its Architecture | A Complete Guide For Beginners
- What is Azure Data Lake ? : Expert’s Top Picks | Everything You Need to Know
- What is Splunk Rex : Step-By-Step Process with REAL-TIME Examples
- What is Data Pipelining? : Step-By-Step Process with REAL-TIME Examples
- Dedup : Splunk Documentation | Step-By-Step Process | Expert’s Top Picks
- What Is a Hadoop Cluster? : A Complete Guide with REAL-TIME Examples
- Spark vs MapReduce | Differences and Which Should You Learn? [ OverView ]
- Top Big Data Challenges With Solutions : A Complete Guide with Best Practices
- Hive vs Impala | What to learn and Why? : All you need to know
- What is Apache Zookeeper? | Expert’s Top Picks | Free Guide Tutorial
- What is HDFS? Hadoop Distributed File System | A Complete Guide [ OverView ]
- Who Is a Data Architect? How to Become and a Data Architect? : Job Description and Required Skills
- Kafka vs RabbitMQ | Differences and Which Should You Learn?
- What is Apache Hadoop YARN? Expert’s Top Picks
- How to install Apache Spark on Windows? : Step-By-Step Process
- What is Big Data Analytics ? Step-By-Step Process
- Top Big Data Certifications for 2020
- What is Hive?
- Big Data Engineer Salary
- How Facebook is Using Big Data?
- Top Influencers in Big Data and Analytics in 2020
- How to Become a Big Data Hadoop Architect?
- What Are the Skills Needed to Learn Hadoop?
- How to Become a Big Data Analyst?
- How Big Data Can Help You Do Wonders In Your Business
- Essential Concepts of Big Data and Hadoop
- How Big Data is Transforming Retail Industry?
- How big Is Big Data?
- How to Become a Hadoop Developer?
- Hadoop Vs Apache Spark
- PySpark Programming

What is Hive?
Last updated on 14th Oct 2020, Artciles, Big Data, Blog
The term ‘Big Data’ is used for collections of large datasets that include huge volume, high velocity, and a variety of data that is increasing day by day. Using traditional data management systems, it is difficult to process Big Data. Therefore, the Apache Software Foundation introduced a framework called Hadoop to solve Big Data management and processing challenges.
Subscribe For Free Demo
Error: Contact form not found.
Hadoop :
Hadoop is an open-source framework to store and process Big Data in a distributed environment. It contains two modules, one is MapReduce and another is Hadoop Distributed File System (HDFS).
- MapReduce: It is a parallel programming model for processing large amounts of structured, semi-structured, and unstructured data on large clusters of commodity hardware.
- HDFS: Hadoop Distributed File System is a part of Hadoop framework, used to store and process the datasets. It provides a fault-tolerant file system to run on commodity hardware.
The Hadoop ecosystem contains different sub-projects (tools) such as Sqoop, Pig, and Hive that are used to help Hadoop modules.
- Sqoop: It is used to import and export data to and from between HDFS and RDBMS.
- Pig: It is a procedural language platform used to develop a script for MapReduce operations.
- Hive: It is a platform used to develop SQL type scripts to do MapReduce operations.
- The traditional approach using Java MapReduce program for structured, semi-structured, and unstructured data.
- The scripting approach for MapReduce to process structured and semi structured data using Pig.
- The Hive Query Language (HiveQL or HQL) for MapReduce to process structured data using Hive.
What is Hive :
Hive is a data warehouse infrastructure tool to process structured data in Hadoop. It resides on top of Hadoop to summarize Big Data, and makes querying and analyzing easy.
Initially Hive was developed by Facebook, later the Apache Software Foundation took it up and developed it further as an open source under the name Apache Hive. It is used by different companies. For example, Amazon uses it in Amazon Elastic MapReduce.
Hive is not :
- A relational database
- A design for OnLine Transaction Processing (OLTP)
- A language for real-time queries and row-level updates
Features of Hive :
- 1. It stores schema in a database and processed data into HDFS.
- 2. It is designed for OLAP.
- 3. It provides SQL type language for querying called HiveQL or HQL.
- 4. It is familiar, fast, scalable, and extensible.
Architecture of Hive :
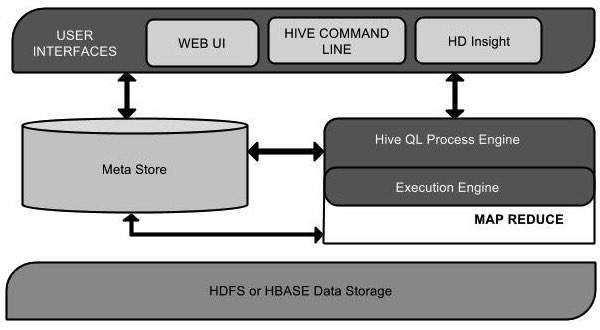
Hive plays a major role in data analysis and business intelligence integration and it supports file formats like text file, rc file. Hive uses a distributed system to process and execute queries and the storage is eventually done on the disk and finally processed using a map-reduce framework. It resolves the optimization problem found under map-reduce and hive perform batch jobs which are clearly explained in the workflow. Here a meta store stores schema information. A framework called Apache Tez is designed for real-time queries performance.
The major components of the Hive are given below:
- 1. Hive clients
- 2. Hive Services
- 3. Hive storage (Meta storage)
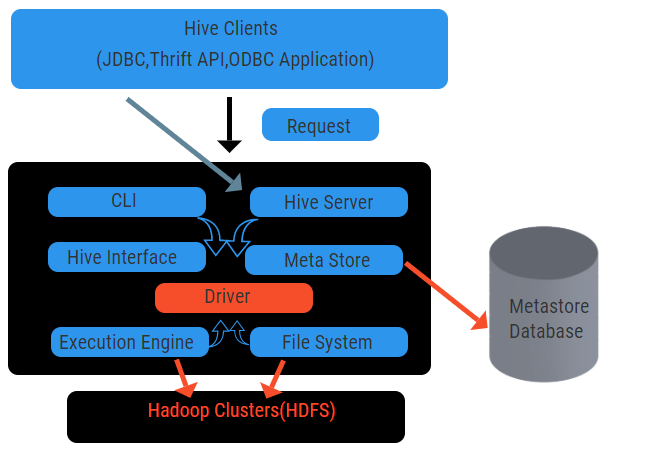
The above diagram shows the architecture of the Hive and its component elements.
Hive Clients
They include Thrift application to execute easy hive commands which are available for python, ruby, C++, and drivers. These client application benefits for executing queries on the hive. Hive has three types of client categorization: thrift clients, JDBC and ODBC clients.
Hive Services
To process all the queries hive has various services. All the functions are easily defined by the user in the hive. Let’s see all those services in brief:
- Command-line interface (User Interface): It enables interaction between the user and the hive, a default shell. It provides a GUI for executing hive command line and hive insight. We can also use web interfaces (HWI) to submit the queries and interactions with a web browser.
- Hive Driver: It receives queries from different sources and clients like thrift server and does store and fetching on ODBC and JDBC driver which are automatically connected to the hive. This component does semantic analysis on seeing the tables from the metastore which parses a query. The driver takes the help of compiler and performs functions like a parser, Planner, Execution of MapReduce jobs and optimizer.
- Compiler: Parsing and semantic process of the query is done by the compiler. It converts the query into an abstract syntax tree and again back into DAG for compatibility. The optimizer, in turn, splits the available tasks. The job of the executor is to run the tasks and monitoring the pipeline schedule of the tasks.
- Execution Engine: All the queries are processed by an execution engine. A DAG stage plans are executed by the engine and help in managing the dependencies between the available stages and execute them on a correct component.
- Metastore: It acts as a central repository to store all the structured information of metadata also it’s an important aspect part for the hive as it has information like tables and partitioning details and the storage of HDFS files. In other words, we shall say metastore acts as a namespace for tables. Metastore is considered to be a separate database that is shared by other components too. Metastore has two pieces called service and backlog storage.
The hive data model is structured into Partitions, buckets, tables. All these can be filtered, have partition keys and to evaluate the query. Hive query works on the Hadoop framework, not on the traditional database. Hive server is an interface between a remote client queries to the hive. The execution engine is completely embedded in a hive server. You could find hive application in machine learning, business intelligence in the detection process.

Learn On-Demand Hive Certification Course from Real Time Experts
Weekday / Weekend BatchesSee Batch DetailsThe following component diagram depicts the architecture of Hive:
Work Flow of Hive
Hive works in two types of modes: interactive mode and non-interactive mode. Former mode allows all the hive commands to go directly to hive shell while the later type executes code in console mode. Data are divided into partitions which further splits into buckets. Execution plans are based on aggregation and data skew. An added advantage of using hive is it easily process large scale of information and has more user interfaces.
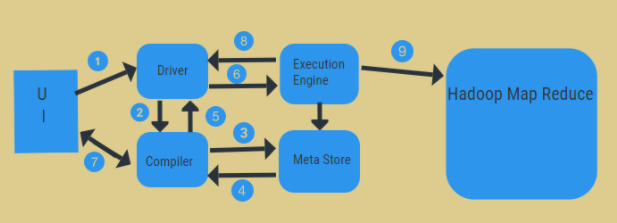
From the above diagram, we can have a glimpse of data flow in the hive with the Hadoop system.
The steps include:
- 1. execute the Query from UI
- 2. get a plan from the driver tasks DAG stages
- 3. get metadata request from the meta store
- 4. send metadata from the compiler
- 5. sending the plan back to the driver
- 6. Execute plan in the execution engine
- 7. fetching results for the appropriate user query
- 8. sending results bi-directionally
- 9. execution engine processing in HDFS with the map-reduce and fetch results from the data nodes created by the job tracker. it acts as a connector between Hive and Hadoop.
The job of the execution engine is to communicate with nodes to get the information stored in the table. Here SQL operations like create, drop, alter are performed to access the table.
This component diagram contains different units. The following table describes each unit:
| Unit Name | Operation |
|---|---|
| User Interface | Hive is a data warehouse infrastructure software that can create interaction between user and HDFS. The user interfaces that Hive supports are Hive Web UI, Hive command line, and Hive HD Insight (In Windows server). |
| Meta Store | Hive chooses respective database servers to store the schema or Metadata of tables, databases, columns in a table, their data types, and HDFS mapping. |
| HiveQL Process Engine | HiveQL is similar to SQL for querying on schema info on the Metastore. It is one of the replacements of traditional approach for MapReduce program. Instead of writing MapReduce program in Java, we can write a query for MapReduce job and process it. |
| Execution Engine | The conjunction part of HiveQL process Engine and MapReduce is Hive Execution Engine. Execution engine processes the query and generates results as same as MapReduce results. It uses the flavor of MapReduce. |
| HDFS or HBASE | Hadoop distributed file system or HBASE are the data storage techniques to store data into file system. |
Benefits of Apache Hive
Apache Hive is ideal for running end-of-day reports, reviewing daily transactions, making ad-hoc queries, and performing data analysis. Such deep insights made available by Apache Hive render significant competitive advantages and make it easier for you to react to market demands.
Following are a few of the benefits that make such insights readily available:
- Ease of use — Querying data is easy to learn with its SQL-like language.
- Accelerated initial insertion of data — Data does not have to be read, parsed, and serialized to a disk in the database’s internal format, since Apache Hive reads the schema without checking the table type or schema definition. Compare this to a traditional database where data must be verified each time it is inserted.
- Superior scalability, flexibility, and cost efficiency — Apache Hive stores 100s of petabytes of data, since it stores data in the HDFS, making it a much more scalable solution than a traditional database. As a cloud-based Hadoop service, Apache Hive enables users to rapidly spin virtual servers up or down to accommodate fluctuating workloads.
- Streamlined security — Critical workloads can be replicated for disaster recovery.
- Low overhead — Insert-only tables have near-zero overhead. Since there is no renaming required, the solution is cloud friendly.
- Exceptional working capacity — Huge datasets support up to 100,000 queries/hour.
Why should we use the Hive?
Along with data analysis hive provides a wide range of options to store the data into HDFS. Hive supports different file systems like a flat file or text file, sequence file consisting of binary key-value pairs, RC files that stores column of a table in a columnar database. Nowadays the file that is most suitable with Hive is known as ORC files or Optimized Row Columnar files.
Why do we need Hive?
In today’s world Hadoop is associated with the most spread technologies that are used for big data processing. The very rich collection of tools and technologies that are used for data analysis and other big data processing.
Who is the right audience for learning Hive technologies?
Majorly people having a background as developers, Hadoop analytics, system administrators, data warehousing, SQL professional, and Hadoop administration can master of the hive.
How this technology will help you in career growth?
Hive is one of the hot skills in the market nowadays and it is one of the best tools for data analysis in the big data Hadoop world. Big enterprises doing analysis over large data sets are always looking for people with the rights of skills so can manage and query huge volumes of data. Hive is one of the best tool available in the market in big data technologies in recent days that can help an organization around the world for their data analysis.
Conclusion
Apart from the above-given functions hive has much more advanced capabilities. The power of hive to process a large number of datasets with great accuracy makes hive one best tool used for analytics in the big data platform. Besides, it also has great potential to emerge as one of the leading big data analytics tools in coming days due to periodic improvement and ease of use for the end user.