
- 10 Best Data Analytics Tools for Big Data Analysis | Everything You Need to Know
- What is Azure Databricks | A Complete Guide with Best Practices
- Elasticsearch Nested Mapping : The Ultimate Guide with Expert’s Top Picks
- Various Talend Products and their Features | Expert’s Top Picks with REAL-TIME Examples
- What is Apache Pig ? : A Definitive Guide | Everything You Need to Know [ OverView ]
- Introduction to HBase and Its Architecture | A Complete Guide For Beginners
- What is Azure Data Lake ? : Expert’s Top Picks | Everything You Need to Know
- What is Splunk Rex : Step-By-Step Process with REAL-TIME Examples
- What is Data Pipelining? : Step-By-Step Process with REAL-TIME Examples
- Dedup : Splunk Documentation | Step-By-Step Process | Expert’s Top Picks
- What Is a Hadoop Cluster? : A Complete Guide with REAL-TIME Examples
- Spark vs MapReduce | Differences and Which Should You Learn? [ OverView ]
- Top Big Data Challenges With Solutions : A Complete Guide with Best Practices
- Hive vs Impala | What to learn and Why? : All you need to know
- What is Apache Zookeeper? | Expert’s Top Picks | Free Guide Tutorial
- What is HDFS? Hadoop Distributed File System | A Complete Guide [ OverView ]
- Who Is a Data Architect? How to Become and a Data Architect? : Job Description and Required Skills
- Kafka vs RabbitMQ | Differences and Which Should You Learn?
- What is Apache Hadoop YARN? Expert’s Top Picks
- How to install Apache Spark on Windows? : Step-By-Step Process
- What is Big Data Analytics ? Step-By-Step Process
- Top Big Data Certifications for 2020
- What is Hive?
- Big Data Engineer Salary
- How Facebook is Using Big Data?
- Top Influencers in Big Data and Analytics in 2020
- How to Become a Big Data Hadoop Architect?
- What Are the Skills Needed to Learn Hadoop?
- How to Become a Big Data Analyst?
- How Big Data Can Help You Do Wonders In Your Business
- Essential Concepts of Big Data and Hadoop
- How Big Data is Transforming Retail Industry?
- How big Is Big Data?
- How to Become a Hadoop Developer?
- Hadoop Vs Apache Spark
- PySpark Programming
- 10 Best Data Analytics Tools for Big Data Analysis | Everything You Need to Know
- What is Azure Databricks | A Complete Guide with Best Practices
- Elasticsearch Nested Mapping : The Ultimate Guide with Expert’s Top Picks
- Various Talend Products and their Features | Expert’s Top Picks with REAL-TIME Examples
- What is Apache Pig ? : A Definitive Guide | Everything You Need to Know [ OverView ]
- Introduction to HBase and Its Architecture | A Complete Guide For Beginners
- What is Azure Data Lake ? : Expert’s Top Picks | Everything You Need to Know
- What is Splunk Rex : Step-By-Step Process with REAL-TIME Examples
- What is Data Pipelining? : Step-By-Step Process with REAL-TIME Examples
- Dedup : Splunk Documentation | Step-By-Step Process | Expert’s Top Picks
- What Is a Hadoop Cluster? : A Complete Guide with REAL-TIME Examples
- Spark vs MapReduce | Differences and Which Should You Learn? [ OverView ]
- Top Big Data Challenges With Solutions : A Complete Guide with Best Practices
- Hive vs Impala | What to learn and Why? : All you need to know
- What is Apache Zookeeper? | Expert’s Top Picks | Free Guide Tutorial
- What is HDFS? Hadoop Distributed File System | A Complete Guide [ OverView ]
- Who Is a Data Architect? How to Become and a Data Architect? : Job Description and Required Skills
- Kafka vs RabbitMQ | Differences and Which Should You Learn?
- What is Apache Hadoop YARN? Expert’s Top Picks
- How to install Apache Spark on Windows? : Step-By-Step Process
- What is Big Data Analytics ? Step-By-Step Process
- Top Big Data Certifications for 2020
- What is Hive?
- Big Data Engineer Salary
- How Facebook is Using Big Data?
- Top Influencers in Big Data and Analytics in 2020
- How to Become a Big Data Hadoop Architect?
- What Are the Skills Needed to Learn Hadoop?
- How to Become a Big Data Analyst?
- How Big Data Can Help You Do Wonders In Your Business
- Essential Concepts of Big Data and Hadoop
- How Big Data is Transforming Retail Industry?
- How big Is Big Data?
- How to Become a Hadoop Developer?
- Hadoop Vs Apache Spark
- PySpark Programming

What is Apache Pig ? : A Definitive Guide | Everything You Need to Know [ OverView ]
Last updated on 03rd Nov 2022, Artciles, Big Data, Blog
- In this article you will learn:
- 1.What is a Pig in Hadoop?
- 2.Components of Pig.
- 3.How Pig Works and Stages of a Pig Operations.
- 4.Salient Features of Pig.
- 5.Data Model in Pig.
- 6.Pig Execution Modes.
- 7.Pig Interactive Modes.
- 8.Pig Commands.
- 9.Conclusion.
What is a Pig in Hadoop?
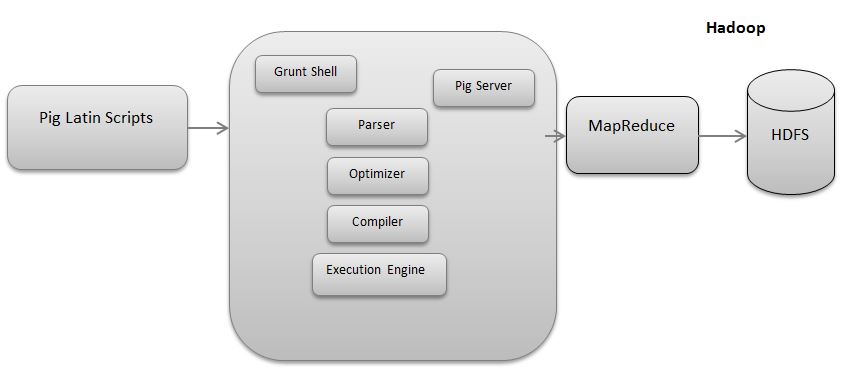
Pig is a scripting platform that runs on Hadoop clusters designed to process and analyse a large datasets. Pig is an extensible, self-optimizing, and also easily programmed.Programmers can use a Pig to write a data transformations without knowing Java. Pig uses both the structured and unstructured data as input to perform analytics and uses HDFS to store results.
Pig – Example:
Yahoo scientists use a grid tools to scan through a petabytes of data. Many of them write a scripts to test a theory or gain deeper insights; however, in data factory, data may not be in standardized state. This makes Pig a good option as it supports the data with partial or unknown schemas and also as semi or unstructured data.
Components of Pig:
There arethe two major components of a Pig:
- Pig Latin script language.
- A runtime engine.
Pig Latin script language:
The Pig Latin script is the procedural data flow language. It contains syntax and commands that can be applied to an implement business logic. Examples of a Pig Latin are LOAD and STORE.
A runtime engine:
The runtime engine is compiler that produces a sequences of a MapReduce programs. It uses HDFS to save and retrieve data. It is also used to interact with a Hadoop system (HDFS and MapReduce).A runtime engine parses, validates, and compiles script operations into a v sequence of MapReduce jobs.

How Pig Works and Stages of a Pig Operations:
Pig operations can be explained in a following three stages:
Stage 1: Load a data and write a Pig script.
In this stage, data is be loaded and Pig script is written.
- A = LOAD ‘myfile’
- AS (x, y, z);
- B = FILTER A by a x > 0
- C = GROUP B BY x;
- D = FOREACH A GENERATE
- x, COUNT(B);
- STORE D INTO ‘output’;
Stage 2: Pig Operations.
In a second stage, Pig execution engine Parses and also checks script. If it passes script optimized and logical and physical plan is generated for execution.The job is be submitted to Hadoop as a job explained as a MapReduce Task. Pig Monitors a status of job using a Hadoop API and reports to a client.
Stage 3: Execution of plan
In a final stage, results are dumped on section or stored in a HDFS depending on user command.
Salient Features of Pig:
Developers and analysts like to use a Pig as it offers more features. Some of features are as follows:
- Provision for a step-by-step procedural control and the ability to an operate directly over files.
- Schemas that, though the optional, can be assigned dynamically.
- Support to the User Defined Functions, or UDFs, and to different data types.
Data Model in Pig:
Atom: It is the simple atomic value like int, long, double, or string.
Tuple: It is the sequence of fields that can be of any data type.
Bag: It is the collection of tuples of potentially varying structures and can contain the duplicates.
Map: It is the associative array.
The key must be a char array, but a value can be of any type. By default, Pig treats undeclared fields as byte arrays, which are collections of an uninterpreted bytes. Pig can infer field’s type based on a use of operators that expect a certain type of field. It can also use User Defined Functions or UFDs, with known or explicitly set the return type. Furthermore, it can infer field type based on a schema information provided by a LOAD function or explicitly declared using a AS clause.
Nested Data Model:
- Pig Latin has fully-nestable data model with the Atomic values, Tuples, Bags or lists, and Maps. This implies a one data type can be nested within a another.
- The advantage is that this is the more natural to programmers than flat Tuples. Also, it avoids the expensive joins. Now will look into various execution modes pig works in.
Pig Execution Modes:
Pig works in a two execution modes: Local and MapReduce:
Local mode:
In a local mode, Pig engine takes input from the Linux file system and the output is stored in same file system. Pig Execution local mode is an explained below.
MapReduce mode:
In MapReduce mode, Pig engine directly interacts and also executes in HDFS and MapReduce.
Pig Interactive Modes:
The two modes in which Pig Latin program can be written Interactive and Batch.
Interactive mode:
In Interactive mode means coding and executing a script, line by line.
Batch mode:
Batch mode, all scripts are coded in a file with the extension .pig and a file is directly executed.
Pig Commands:
Given below in a table are some frequently used a Pig Commands:
| Command | Function |
|---|---|
| Load | Reads data from a system |
| Store | Writes data to the file system |
| Foreach | Applies expressions to every record and outputs one or more records |
| Filter | Applies predicate and removes a records that do not return true |
| Group/cogroup | Collects a records with a same key from one or more inputs |
| join | Joins two or more inputs based on the key |
| order | Sorts records based on the key |
| distinct | Removes a duplicate records |
| union | Merges a data sets |
| split | Splits a data into two or more sets based on a filter conditions |
| stream | Sends all the records through a user-provided binary |
| dump | Writes a output to stdout |
| limit | Limits number of records |
Conclusion:
Pig is a technology that builds a bridge between the Hadoop, Hive and other data management technologies which can be further used to eradicate a problems related to management of big or any size of a data. MapReduce has gone out of style because it is way simpler to write code in Pig and also Apache Spark is partly responsible. On top of it, it is high effective also as we have seen that 10 lines of a MapReduce code is equivalent to the single line of Pig code.