
- HTML Comments Tutorial | Convert Comments into HTML Codes
- Data Structure and Algorithms Tutorial | Ultimate Guide to Learn
- Gradle Tutorial | For Beginners [ STEP-IN ]
- Encapsulation In Java | Complete Tutorial With Examples
- What is Release Management? | A Comprehensive Tutorial for Beginners
- OOPs Concepts in Java | Learn from Basics with Examples
- The Top Basic Tools of Quality Tutorial | The Ultimate Guide
- Set Environment for C# – Learn How to Setup through this Tutorial
- C# Vs Java Tutorial | Overview and Key Difference
- List of IDEs to run C# Programs | Tutorial for Learning Path
- C Sharp Variables and Constants | The Ultimate Guide
- Unsafe Code in C-Sharp Tutorial | Everything You Need to Know
- Type Conversion Method in C# | A Complete Tutorial
- What Is Synchronization in c# Tutorial | The BEST Step-By-Step Guide
- Understanding Structures in C# | Learn in 1 Day FREE Tutorial
- Strings – C# Tutorial | A Definitive Programming Guide
- Static Keyword in C# Tutorial | Learn with Examples
- Stack Collection in C# Tutorial | A Definitive Guide for Beginners
- C# Sorted List Tutorial with Examples | Learn in 1 Day FREE
- C# Serialization Tutorial | Ultimate Guide to Learn [BEST & NEW]
- Regular Expression in C# Tutorial | Everything You Need to Know
- What is Reflection in C#? | Learn Now Tutorial
- Queue Collection in C# Tutorial | A Definitive Guide
- Properties in C# | The complete Tutorial
- C# Preprocessor Directives Tutorial | Learn in 1 Day FREE
- Polymorphism C# Tutorial | The Ultimate Guide
- C# Operators Tutorial | Learn Arithmetic, Comparison, Logical Concepts
- Namespaces – The complete C# Tutorial
- Multithreading in C# Tutorial | Learn With Examples and Advantages
- Methods – C# Tutorial | A Complete Programming Guide
- Linked List Implementation in C# Tutorial | Ultimate Guide to Learn [UPDATED]
- Introduction to C# Tutorial | Guide for Beginners
- What is Interface in C# | A Defined Free Tutorial
- C# Inheritance Tutorial | A Complete Free Tutorial
- Indexers in C# Tutorial | A Complete Programming Guide
- HashSet Collection in C# Tutorial | Complete Guide Tutorial For Free
- Generics in C# Tutorial | Learn Generic Classes and Methods
- Creating Your First C# Program Tutorial | Learn in 1 Day
- Basics of File Handling in C# Tutorial | The Ultimate Guide
- C# Exception Handling Tutorial | Learn with Best Practices
- Events – C# Tutorial | A Complete Programming Guide
- C# Enumerations Type Tutorial | Learn Everything about Enum
- Dictionary Collection in C# | Ultimate Guide to Learn [NEW & UPDATED]
- Delegates – C# Programming Guide | The Ultimate Guide for Beginners
- Understanding Decision Making Statements in C# | Learn Now Tutorial
- Classes and Objects – C# Fundamentals Tutorial
- C# BitArray Collection Tutorial | Learn in 1 Day FREE
- Attributes in C# Tutorial | Learn to work with attributes in C#
- C# Array Tutorial | Create, Declare, Initialize
- ArrayList Collection on in C# | A Complete tutorial For Beginners
- Anonymous Methods and Lambdas – C# Tutorial | A Complete Guide
- Abstraction in C# Tutorial – Learn the Abstract class and Interface
- Game Development using Unity 3D Tutorial | Ultimate Guide to Learn [UPDATED]
- C++ Reference Tutorial | A Comprehensive Guide for Beginners
- PHP vs Python | Which Is Better For Web Development
- C++ Constructors Tutorial: Types and Copy Constructors
- JavaScript Arrays Tutorial | Complete Beginner’s Guide
- What Is Maven | Maven Tutorial For Beginners
- Spring Tutorial | Perfect Guide for Beginners
- React Hooks Tutorial for Beginners | Ultimate Guide to Learn
- Python for Data Science Tutorial | Quickstart : A Complete Guide
- What is Golang? : A tutorial for beginners | Get started
- Hibernate Validator Tutorial | Learn in 1 Day FREE
- Postman Tutorial for Beginners: API Testing using Postman | A Complete Guide
- Akka Tutorial
- J2EE | Web Development Tutorial for Beginners
- Scala Exception Handling Tutorial | Learn in 1 Day [ STEP-IN ]
- Web development Tutorial
- Visual Studio Tutorial
- PyGame Tutorial
- Python Anaconda Tutorial
- Python Scikit-Learn Cheat Sheet Tutorial
- Mean Stack Tutorial
- Python Requests Tutorial
- Advanced Java Tutorial
- Spring Boot Microservices Tutorial
- Java Servlets Tutorial
- How to Install Pycharm
- Pycharm Tutorial
- Python Version Tutorial
- Python strings
- How to Download Python
- C Data Types Tutorial
- arrays in python
- Python While Loop Tutorial
- JAVA Tutorial
- Loops In C Tutorial
- Java File I/O Tutorial
- Variables in Python Tutorial
- Python Tutorial
- Python Pandas Cheat Sheet Tutorial
- Data Structures Cheat Sheet with Python Tutorial
- Python Tuples Tutorial
- Python If Else Statements Tutorial
- Python Functions Tutorial
- HTML Comments Tutorial | Convert Comments into HTML Codes
- Data Structure and Algorithms Tutorial | Ultimate Guide to Learn
- Gradle Tutorial | For Beginners [ STEP-IN ]
- Encapsulation In Java | Complete Tutorial With Examples
- What is Release Management? | A Comprehensive Tutorial for Beginners
- OOPs Concepts in Java | Learn from Basics with Examples
- The Top Basic Tools of Quality Tutorial | The Ultimate Guide
- Set Environment for C# – Learn How to Setup through this Tutorial
- C# Vs Java Tutorial | Overview and Key Difference
- List of IDEs to run C# Programs | Tutorial for Learning Path
- C Sharp Variables and Constants | The Ultimate Guide
- Unsafe Code in C-Sharp Tutorial | Everything You Need to Know
- Type Conversion Method in C# | A Complete Tutorial
- What Is Synchronization in c# Tutorial | The BEST Step-By-Step Guide
- Understanding Structures in C# | Learn in 1 Day FREE Tutorial
- Strings – C# Tutorial | A Definitive Programming Guide
- Static Keyword in C# Tutorial | Learn with Examples
- Stack Collection in C# Tutorial | A Definitive Guide for Beginners
- C# Sorted List Tutorial with Examples | Learn in 1 Day FREE
- C# Serialization Tutorial | Ultimate Guide to Learn [BEST & NEW]
- Regular Expression in C# Tutorial | Everything You Need to Know
- What is Reflection in C#? | Learn Now Tutorial
- Queue Collection in C# Tutorial | A Definitive Guide
- Properties in C# | The complete Tutorial
- C# Preprocessor Directives Tutorial | Learn in 1 Day FREE
- Polymorphism C# Tutorial | The Ultimate Guide
- C# Operators Tutorial | Learn Arithmetic, Comparison, Logical Concepts
- Namespaces – The complete C# Tutorial
- Multithreading in C# Tutorial | Learn With Examples and Advantages
- Methods – C# Tutorial | A Complete Programming Guide
- Linked List Implementation in C# Tutorial | Ultimate Guide to Learn [UPDATED]
- Introduction to C# Tutorial | Guide for Beginners
- What is Interface in C# | A Defined Free Tutorial
- C# Inheritance Tutorial | A Complete Free Tutorial
- Indexers in C# Tutorial | A Complete Programming Guide
- HashSet Collection in C# Tutorial | Complete Guide Tutorial For Free
- Generics in C# Tutorial | Learn Generic Classes and Methods
- Creating Your First C# Program Tutorial | Learn in 1 Day
- Basics of File Handling in C# Tutorial | The Ultimate Guide
- C# Exception Handling Tutorial | Learn with Best Practices
- Events – C# Tutorial | A Complete Programming Guide
- C# Enumerations Type Tutorial | Learn Everything about Enum
- Dictionary Collection in C# | Ultimate Guide to Learn [NEW & UPDATED]
- Delegates – C# Programming Guide | The Ultimate Guide for Beginners
- Understanding Decision Making Statements in C# | Learn Now Tutorial
- Classes and Objects – C# Fundamentals Tutorial
- C# BitArray Collection Tutorial | Learn in 1 Day FREE
- Attributes in C# Tutorial | Learn to work with attributes in C#
- C# Array Tutorial | Create, Declare, Initialize
- ArrayList Collection on in C# | A Complete tutorial For Beginners
- Anonymous Methods and Lambdas – C# Tutorial | A Complete Guide
- Abstraction in C# Tutorial – Learn the Abstract class and Interface
- Game Development using Unity 3D Tutorial | Ultimate Guide to Learn [UPDATED]
- C++ Reference Tutorial | A Comprehensive Guide for Beginners
- PHP vs Python | Which Is Better For Web Development
- C++ Constructors Tutorial: Types and Copy Constructors
- JavaScript Arrays Tutorial | Complete Beginner’s Guide
- What Is Maven | Maven Tutorial For Beginners
- Spring Tutorial | Perfect Guide for Beginners
- React Hooks Tutorial for Beginners | Ultimate Guide to Learn
- Python for Data Science Tutorial | Quickstart : A Complete Guide
- What is Golang? : A tutorial for beginners | Get started
- Hibernate Validator Tutorial | Learn in 1 Day FREE
- Postman Tutorial for Beginners: API Testing using Postman | A Complete Guide
- Akka Tutorial
- J2EE | Web Development Tutorial for Beginners
- Scala Exception Handling Tutorial | Learn in 1 Day [ STEP-IN ]
- Web development Tutorial
- Visual Studio Tutorial
- PyGame Tutorial
- Python Anaconda Tutorial
- Python Scikit-Learn Cheat Sheet Tutorial
- Mean Stack Tutorial
- Python Requests Tutorial
- Advanced Java Tutorial
- Spring Boot Microservices Tutorial
- Java Servlets Tutorial
- How to Install Pycharm
- Pycharm Tutorial
- Python Version Tutorial
- Python strings
- How to Download Python
- C Data Types Tutorial
- arrays in python
- Python While Loop Tutorial
- JAVA Tutorial
- Loops In C Tutorial
- Java File I/O Tutorial
- Variables in Python Tutorial
- Python Tutorial
- Python Pandas Cheat Sheet Tutorial
- Data Structures Cheat Sheet with Python Tutorial
- Python Tuples Tutorial
- Python If Else Statements Tutorial
- Python Functions Tutorial

Python Scikit-Learn Cheat Sheet Tutorial
Last updated on 12th Oct 2020, Blog, Software Engineering, Tutorials
What is scikit-learn or sklearn?
Scikit-learn is probably the most useful library for machine learning in Python. The sklearn library contains a lot of efficient tools for machine learning and statistical modeling including classification, regression, clustering and dimensionality reduction.
Please note that sklearn is used to build machine learning models. It should not be used for reading the data, manipulating and summarizing it. There are better libraries for that (e.g. NumPy, Pandas etc.)
Components of scikit-learn:
Scikit-learn comes loaded with a lot of features. Here are a few of them to help you understand the spread
Supervised learning algorithms:
Think of any supervised machine learning algorithm you might have heard about and there is a very high chance that it is part of scikit-learn. Starting from Generalized linear models (e.g Linear Regression), Support Vector Machines (SVM), Decision Trees to Bayesian methods – all of them are part of scikit-learn toolbox. The spread of machine learning algorithms is one of the big reasons for the high usage of scikit-learn. I started using scikit to solve supervised learning problems and would recommend that to people new to scikit / machine learning as well.
Cross-validation:
There are various methods to check the accuracy of supervised models on unseen data using sklearn.
Unsupervised learning algorithms:
Again there is a large spread of machine learning algorithms in the offering – starting from clustering, factor analysis, principal component analysis to unsupervised neural networks.
Various toy datasets:
This came in handy while learning scikit-learn. I had learned SAS using various academic datasets (e.g. IRIS dataset, Boston House prices dataset). Having them handy while learning a new library helped a lot.
Feature extraction:
Scikit-learn for extracting features from images and text (e.g. Bag of words)
Community / Organizations using scikit-learn:
One of the main reasons behind using open source tools is the huge community it has. Same is true for sklearn as well. There are about 35 contributors to scikit-learn till date, the most notable being Andreas Mueller (P.S. Andy’s machine learning cheat sheet is one of the best visualizations to understand the spectrum of machine learning algorithms).
There are various Organizations of the likes of Evernote, Inria and AWeber which are being displayed on scikit learn home page as users. But I truly believe that the actual usage is far more.
In addition to these communities, there are various meetups across the globe. There was also a Kaggle knowledge contest, which finished recently but might still be one of the best places to start playing around with the library.
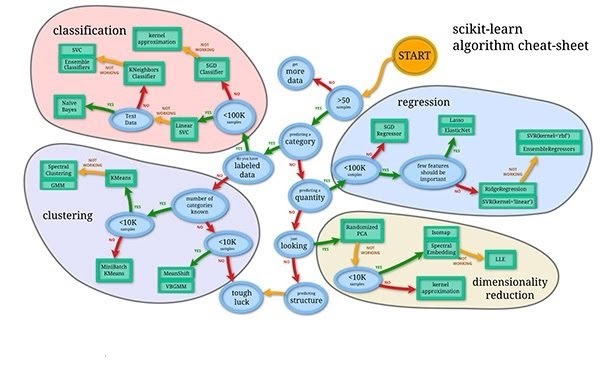
Machine Learning cheat sheet – see Original image for better resolution
Interfaces
The library is organized around three fundamental APIs (interfaces): Estimator, Predictor, and Transformer. Importantly and crucially these interfaces are complementary; they do not represent hard boundaries between classes or precise semantic separation, but rather an overlap. For example, the DecisionTree classifier is both an Estimator and a Predictor — more on this in a bit.
Estimators
Estimators represent the core interface in Scikit-Learn. All learning algorithms, whether supervised or unsupervised, classification, regression, or clustering, implement the Estimator interface and expose a fit method.
An Estimator’s fit method takes as input a (training) feature vector (“samples” or “predictors”) as well as (training) target labels (in the case of supervised learning), and in this way the estimator “learns” how to make predictions on unseen data (again, in the case of supervised learning).
A key design principle is that the instantiation of an Estimator (where, for example, you denote a model’s hyper-parameters) is decoupled from the learning process (where you fit the model with training data — your feature vectors, e.g., “X_train”; as well as your training labels/target variables, e.g., “Y_train”). That is, when you construct an Estimator (such as a DecisionTree classifier, as noted earlier), you pass in hyper-parameters, but you do not pass in the training data; the training data is passed in via the fit method. As noted in the “API Design…” paper, this separation is similar to the idea of “partial function application”, where certain arguments are bound — or frozen — to one function, and then that function (with its frozen arguments) is passed to another function — a kind of higher-order function, or functional composition. Indeed, this “pattern”, as it were, is supported by the Python standard library, through functools.partial.
Subscribe For Free Demo
Error: Contact form not found.
Predictors
One of the confusing aspects of Scikit-Learn’s interface choices is the separation of Predictors from Estimators; Predictors extend the Estimator interface, and for a given model to “work” it must implement (and expose) a predict method. Indeed, Scikit-Learn’s glossary denotes a Predictor as “an estimator supporting predict and/or fit_predict.” Yet Scikit-Learn semantically separates these two notions through the API. Although this is not a tutorial on how to use the library, and though this may be stating the obvious, the predict method that a model implements as part of the Predictor interface does the work of predicting results — given test features; and after a model is trained, the predictor returns predicted labels for a given input feature vector. Predictors may also provide probabilities as well as prediction scores, which is part of another Design principle (discussed shortly).
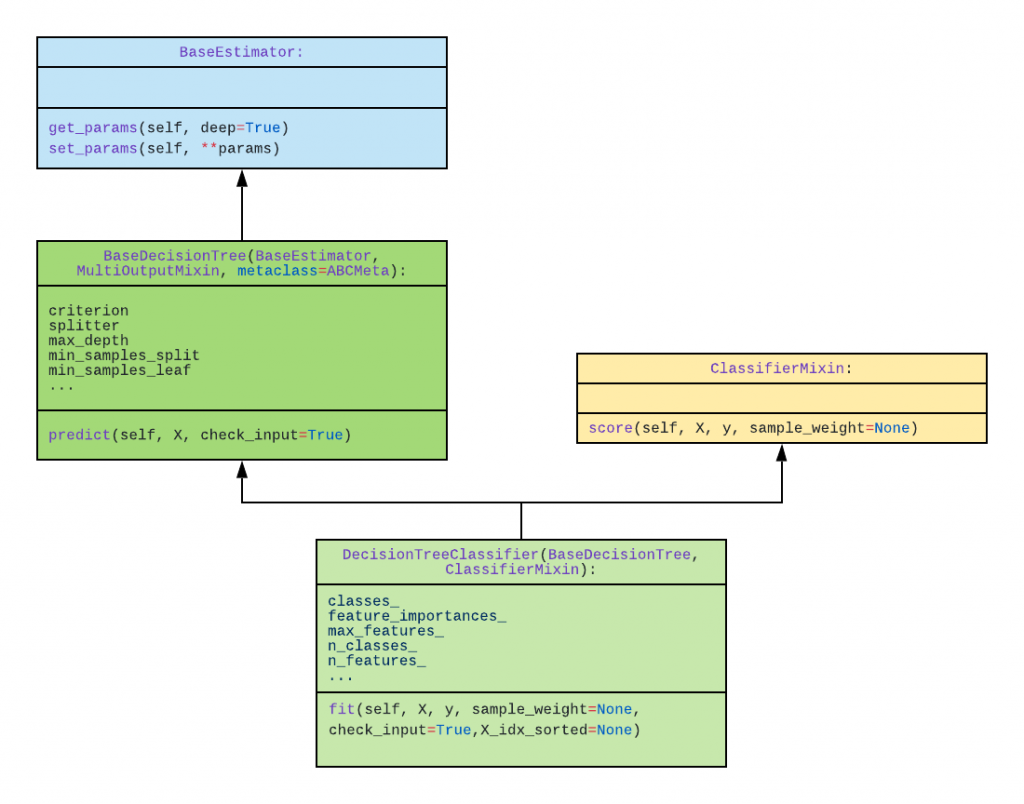
Transformers
Not surprisingly, Transformers modify data. The “API Design…” paper states it best:Like models, transformers also need to be fitted and, once done, their transform method may be invoked. In keeping with the elegant and consistent simplicity of the library, the fit method always returns the estimator it was called on, allowing you to chain the fit and transform methods. For convenience, transformers also support a fit_transform method as well, so users may do both in one step.
The class diagram denoted below shows how the StandardScaler transformer is also an Estimator, and also mixes in the TransformerMixin class. However, the code to use this transformer is — once again — remarkably straightforward.
Transparency
All of the hyper-parameters used to construct estimators and transformers, as well as the results of fitting and prediction, are visible to users of the interface as public attributes. Superficially this may seem to contravene the encapsulation and information hiding principles that have long been a hallmark of object-oriented design, where object state is usually made available only through the mediation of class methods. But this design choice greatly simplifies the library (by obviating the proliferation of access methods): because the interface is already consistent (and both lucid and cogent), adding gratuitous methods to fetch key model attributes or prediction results would only diminish its effectiveness.
Core Data Structures
The library’s designers likewise made a straightforward and concrete decision to base the core data representations needed for machine learning on Numpy multi-dimensional arrays — rather than introduce a bespoke set of classes to encapsulate data representing features and labels/targets. As with many other choices, this reduces the barrier to entry, as it were — a user doesn’t have to learn a new class hierarchy for machine learning data representation — as well as ensures performance in terms of both time and space, given that Numpy is optimized for performance using C.
Composing Estimators Pipelines
The consistent and uniform interface across all the core semantic components — Estimators, Predictors, and Transformers — affords the library additional power and flexibility in allowing users to compose new, or augmented, functionality through a chaining together of estimators. Keeping in mind that transformers are a kind of estimator (recall the class diagram for the StandardScaler above, deriving from BaseEstimator), Scikit-Learn provides a Pipeline class that allows a user to chain together multiple transformers; because all transformers share the same interface, the pipeline can fit a user’s data to all the transformers (by iterating over the collection of transformers it has been constructed with), and then, if fit_transform is also called, applying the transformations and returning the transformed data. The code snippet below demonstrates how easy it is to fill in missing values with the mean of similar features (through the SimpleImputer class), and then scale the data (through the StandardScaler class).
Extensibility Through Duck-Typing
The last design principle I want to mention is the library’s reliance on so-called duck-typing to allow for extensions to the library. Duck-typing means that if a class supports a specific method — i.e., if it “looks like a duck” — then it can be used interchangeably with other objects of the same interface — i.e., it is a duck. This avoids the need for inheritance, which in theory makes the code less tightly coupled, brittle, and complex. That is, if a user wants to extend the library, for example, by writing a custom transformer, they do not necessarily need to inherit from Scikit-Learn classes. In this way the library’s creators bring Pythonic flexibility and pragmatism to Scikit-Learn.
Linear Regression is a machine learning algorithm based on supervised learning. It performs a regression task. Regression models a target prediction value based on independent variables. It is mostly used for finding out the relationship between variables and forecasting.
Different regression models differ based on — the kind of relationship between dependent and independent variables, they are considering and the number of independent variables being used.
Naive Bayes
The Naive Bayes classifier is suitable for classification with discrete features (e.g., word counts for text classification). The multinomial distribution normally requires integer feature counts. However, in practice, fractional counts such as tf-idf may also work.

Best JOB Oriented Python Training With Industry Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
K-Nearest Neighbors
Neighbors-based classification is a type of instance-based learning or non-generalizing learning: it does not attempt to construct a general internal model, but simply stores instances of the training data. Classification is computed from a simple majority vote of the nearest neighbors of each point: a query point is assigned the data class which has the most representatives within the nearest neighbors of the point.
K-Means
The K-Means algorithm clusters data by trying to separate samples in n groups of equal variance, minimizing a criterion known as the inertia or within-cluster sum-of-squares (see below). This algorithm requires the number of clusters to be specified. It scales well to a large number of samples and has been used across a large range of application areas in many different fields.
Scikit Learn Cheat Sheet Python Machine Learning
An easy-to-follow scikit learn tutorial that will help you to get started with Python machine learning. A handy scikit-learn cheat sheet to machine learning with Python, this includes the function and its brief description
Pre-Processing
Function |
Description |
| sklearn.preprocessing.StandardScaler | Standardize features by removing the mean and scaling to unit variance |
| sklearn.preprocessing.Imputer | Imputation transformer for completing missing values |
| sklearn.preprocessing.LabelBinarizer | Binarize labels in a one-vs-all fashion |
| sklearn.preprocessing.OneHotEncoder | Encode categorical integer features using a one-hot a.k.a one-of-K scheme |
| sklearn.preprocessing.PolynomialFeatures | Generate polynomial and interaction features |
Regression
Function |
Description |
| sklearn.tree.DecisionTreeRegressor | A decision tree regressor |
| sklearn.svm.SVR | Epsilon-Support Vector Regression |
| sklearn.linear_model.LinearRegression | Ordinary least squares Linear Regression |
| sklearn.linear_model.Lasso | Linear Model trained with L1 prior as regularized (a.k.a the lasso) |
| sklearn.linear_model.SGDRegressor | Linear model fitted by minimizing a regularized empirical loss with SGD |
| sklearn.linear_model.ElasticNet | Linear regression with combined L1 and L2 priors as regularizer |
| sklearn.ensemble.RandomForestRegressor | A random forest regressor |
| sklearn.ensemble.GradientBoostingRegressor | Gradient Boosting for regression |
| sklearn.neural_network.MLPRegressor | Multi-layer Perceptron regressor |
classification
Function |
Description |
| sklearn.neural_network.MLPClassifier | Multi-layer Perceptron classifier |
| sklearn.tree.DecisionTreeClassifier | A decision tree classifier |
| sklearn.svm.SVC | C-Support Vector Classification |
| sklearn.linear_model.LogisticRegression | Logistic Regression (a.k.a logit, Max Ent) classifier |
| sklearn.linear_model.SGDClassifier | Linear classifiers (SVM, logistic regression, a.o.) with SGD training |
| sklearn.naive_bayes.GaussianNB | Gaussain Naïve Bayes |
| sklearn.neighbors.KNeighborsClassifier | Classifier implementing the k-nearest neighbors vote |
| sklearn.ensemble.RandomForestClassifier | A random forest classifier |
| sklearn.ensemble.GradientBoostingClassifier | Gradient Boosting for classification |
Clustering
Function |
Description |
| sklearn.cluster.Kmeans | K-Means clustering |
| sklearn.cluster.DBSCAN | perform DBSCAN clustering from vector array or distance matrix |
| sklearn.cluster.AgglomerativeClustering | Agglomerative clustering |
| sklearn.cluster.SpectralBiclustering | Spectral bi-clustering |
Dimensionality Reduction
Function |
Description |
| sklearn.decomposition.PCA | Principal component analysis (PCA) |
| sklearn.decomposition.LatentDirichletAllocation | Latent Dirichlet Allocation with online variational Bayes algorithm |
| sklearn.decomposition.SparseCoder | Sparse coding |
| sklearn.decomposition.DictionaryLearning | Dictionary learning |
Metric
Function |
Description |
| sklearn.metrics.accuracy_score | Classification Metric: Accuracy classification score |
| sklearn.metrics.log_loss | Classification Metric: Log loss, a.k.a logistic loss or cross-entropy loss |
| sklearn.metrics.roc_auc_score | Classification Metric: Compute Receiver operating characteristics ROC |
| sklearn.metrics.mean_absolute_error | Regression Metric: Mean absolute error regression loss |
| sklearn.metrics.r2_score | Regression Metric: R^2 (coefficient of determination) regression score |
| sklearn.metrics.label_ranking_loss | Ranking Metric: Compute Ranking loss measure |
| sklearn.metrics.mutual_info_score | Clustering Metric: Mutual Information between two clustering. |
Miscellaneous
Function |
Description |
| sklearn.datasets.load_boston | Load and return the Boston house prices data set (regression) |
| sklearn.datasets.make_classification | Generate a random n-class classification problem |
| sklearn.feature_extraction.FeatureHasher | Implements feature hashing, a.k.a the hashing trick |
| sklearn.feature_selection.SelectKBest | Select features according to the k highest scores |
| sklearn.pipeline.Pipeline | Pipeline of transforms with a final estimator |
| sklearn.semi_supervised.LabelPropagation | Label Propagation classifier for semi-supervised learning |
Conclusion
Data scientists, whether students or professionals, are fortunate to have such a profoundly rich and well-designed library such as Scikit-Learn, which allows us to tackle complex machine learning problems with beautiful and well-designed code.