
- What is Dimension Reduction? | Know the techniques
- Top Data Science Software Tools
- What is Data Scientist? | Know the skills required
- What is Data Scientist ? A Complete Overview
- Know the difference between R and Python
- What are the skills required for Data Science? | Know more about it
- What is Python Data Visualization ? : A Complete guide
- Data science and Business Analytics? : All you need to know [ OverView ]
- Supervised Learning Workflow and Algorithms | A Definitive Guide with Best Practices [ OverView ]
- Open Datasets for Machine Learning | A Complete Guide For Beginners with Best Practices
- What is Data Cleaning | The Ultimate Guide for Data Cleaning , Benefits [ OverView ]
- What is Data Normalization and Why it is Important | Expert’s Top Picks
- What does the Yield keyword do and How to use Yield in python ? [ OverView ]
- What is Dimensionality Reduction? : ( A Complete Guide with Best Practices )
- What You Need to Know About Inferential Statistics to Boost Your Career in Data Science | Expert’s Top Picks
- Most Effective Data Collection Methods | A Complete Beginners Guide | REAL-TIME Examples
- Most Popular Python Toolkit : Step-By-Step Process with REAL-TIME Examples
- Advantages of Python over Java in Data Science | Expert’s Top Picks [ OverView ]
- What Does a Data Analyst Do? : Everything You Need to Know | Expert’s Top Picks | Free Guide Tutorial
- How To Use Python Lambda Functions | A Complete Beginners Guide [ OverView ]
- Most Popular Data Science Tools | A Complete Beginners Guide | REAL-TIME Examples
- What is Seaborn in Python ? : A Complete Guide For Beginners & REAL-TIME Examples
- Stepwise Regression | Step-By-Step Process with REAL-TIME Examples
- Skewness vs Kurtosis : Comparision and Differences | Which Should You Learn?
- What is the Future scope of Data Science ? : Comprehensive Guide [ For Freshers and Experience ]
- Confusion Matrix in Python Sklearn | A Complete Beginners Guide | REAL-TIME Examples
- Polynomial Regression | All you need to know [ Job & Future ]
- What is a Web Crawler? : Expert’s Top Picks | Everything You Need to Know
- Pandas vs Numpy | What to learn and Why? : All you need to know
- What Is Data Wrangling? : Step-By-Step Process | Required Skills [ OverView ]
- What Does a Data Scientist Do? : Step-By-Step Process
- Data Analyst Salary in India [For Freshers and Experience]
- Elasticsearch vs Solr | Difference You Should Know
- Tools of R Programming | A Complete Guide with Best Practices
- How To Install Jenkins on Ubuntu | Free Guide Tutorial
- Skills Required to Become a Data Scientist | A Complete Guide with Best Practices
- Applications of Deep Learning in Daily Life : A Complete Guide with Best Practices
- Ridge and Lasso Regression (L1 and L2 regularization) Explained Using Python – Expert’s Top Picks
- Simple Linear Regression | Expert’s Top Picks
- Dispersion in Statistics – Comprehensive Guide
- Future Scope of Machine Learning | Everything You Need to Know
- What is Data Analysis ? Expert’s Top Picks
- Covariance vs Correlation | Difference You Should Know
- Highest Paying Jobs in India [ Job & Future ]
- What is Data Collection | Step-By-Step Process
- What Is Data Processing ? A Step-By-Step Guide
- Data Analyst Job Description ( A Complete Guide with Best Practices )
- What is Data ? All you need to know [ OverView ]
- What Is Cleaning Data ?
- What is Data Scrubbing?
- Data Science vs Data Analytics vs Machine Learning
- How to Use IF ELSE Statements in Python?
- What are the Analytical Skills Necessary for a Successful Career in Data Science?
- Python Career Opportunities
- Top Reasons To Learn Python
- Python Generators
- Advantages and Disadvantages of Python Programming Language
- Python vs R vs SAS
- What is Logistic Regression?
- Why Python Is Essential for Data Analysis and Data Science
- Data Mining Vs Statistics
- Role of Citizen Data Scientists in Today’s Business
- What is Normality Test in Minitab?
- Reasons You Should Learn R, Python, and Hadoop
- A Day in the Life of a Data Scientist
- Top Data Science Programming Languages
- Top Python Libraries For Data Science
- Machine Learning Vs Deep Learning
- Big Data vs Data Science
- Why Data Science Matters And How It Powers Business Value?
- Top Data Science Books for Beginners and Advanced Data Scientist
- Data Mining Vs. Machine Learning
- The Importance of Machine Learning for Data Scientists
- What is Data Science?
- Python Keywords
- What is Dimension Reduction? | Know the techniques
- Top Data Science Software Tools
- What is Data Scientist? | Know the skills required
- What is Data Scientist ? A Complete Overview
- Know the difference between R and Python
- What are the skills required for Data Science? | Know more about it
- What is Python Data Visualization ? : A Complete guide
- Data science and Business Analytics? : All you need to know [ OverView ]
- Supervised Learning Workflow and Algorithms | A Definitive Guide with Best Practices [ OverView ]
- Open Datasets for Machine Learning | A Complete Guide For Beginners with Best Practices
- What is Data Cleaning | The Ultimate Guide for Data Cleaning , Benefits [ OverView ]
- What is Data Normalization and Why it is Important | Expert’s Top Picks
- What does the Yield keyword do and How to use Yield in python ? [ OverView ]
- What is Dimensionality Reduction? : ( A Complete Guide with Best Practices )
- What You Need to Know About Inferential Statistics to Boost Your Career in Data Science | Expert’s Top Picks
- Most Effective Data Collection Methods | A Complete Beginners Guide | REAL-TIME Examples
- Most Popular Python Toolkit : Step-By-Step Process with REAL-TIME Examples
- Advantages of Python over Java in Data Science | Expert’s Top Picks [ OverView ]
- What Does a Data Analyst Do? : Everything You Need to Know | Expert’s Top Picks | Free Guide Tutorial
- How To Use Python Lambda Functions | A Complete Beginners Guide [ OverView ]
- Most Popular Data Science Tools | A Complete Beginners Guide | REAL-TIME Examples
- What is Seaborn in Python ? : A Complete Guide For Beginners & REAL-TIME Examples
- Stepwise Regression | Step-By-Step Process with REAL-TIME Examples
- Skewness vs Kurtosis : Comparision and Differences | Which Should You Learn?
- What is the Future scope of Data Science ? : Comprehensive Guide [ For Freshers and Experience ]
- Confusion Matrix in Python Sklearn | A Complete Beginners Guide | REAL-TIME Examples
- Polynomial Regression | All you need to know [ Job & Future ]
- What is a Web Crawler? : Expert’s Top Picks | Everything You Need to Know
- Pandas vs Numpy | What to learn and Why? : All you need to know
- What Is Data Wrangling? : Step-By-Step Process | Required Skills [ OverView ]
- What Does a Data Scientist Do? : Step-By-Step Process
- Data Analyst Salary in India [For Freshers and Experience]
- Elasticsearch vs Solr | Difference You Should Know
- Tools of R Programming | A Complete Guide with Best Practices
- How To Install Jenkins on Ubuntu | Free Guide Tutorial
- Skills Required to Become a Data Scientist | A Complete Guide with Best Practices
- Applications of Deep Learning in Daily Life : A Complete Guide with Best Practices
- Ridge and Lasso Regression (L1 and L2 regularization) Explained Using Python – Expert’s Top Picks
- Simple Linear Regression | Expert’s Top Picks
- Dispersion in Statistics – Comprehensive Guide
- Future Scope of Machine Learning | Everything You Need to Know
- What is Data Analysis ? Expert’s Top Picks
- Covariance vs Correlation | Difference You Should Know
- Highest Paying Jobs in India [ Job & Future ]
- What is Data Collection | Step-By-Step Process
- What Is Data Processing ? A Step-By-Step Guide
- Data Analyst Job Description ( A Complete Guide with Best Practices )
- What is Data ? All you need to know [ OverView ]
- What Is Cleaning Data ?
- What is Data Scrubbing?
- Data Science vs Data Analytics vs Machine Learning
- How to Use IF ELSE Statements in Python?
- What are the Analytical Skills Necessary for a Successful Career in Data Science?
- Python Career Opportunities
- Top Reasons To Learn Python
- Python Generators
- Advantages and Disadvantages of Python Programming Language
- Python vs R vs SAS
- What is Logistic Regression?
- Why Python Is Essential for Data Analysis and Data Science
- Data Mining Vs Statistics
- Role of Citizen Data Scientists in Today’s Business
- What is Normality Test in Minitab?
- Reasons You Should Learn R, Python, and Hadoop
- A Day in the Life of a Data Scientist
- Top Data Science Programming Languages
- Top Python Libraries For Data Science
- Machine Learning Vs Deep Learning
- Big Data vs Data Science
- Why Data Science Matters And How It Powers Business Value?
- Top Data Science Books for Beginners and Advanced Data Scientist
- Data Mining Vs. Machine Learning
- The Importance of Machine Learning for Data Scientists
- What is Data Science?
- Python Keywords

What Is Cleaning Data ?
Last updated on 14th Oct 2020, Artciles, Blog, Data Science
- In this article you will get
- What is data cleaning?
- What is difference between the data cleaning and data transformation?
- How to clean data?
- Components of quality data
- Conclusion
What is data cleaning?
Data cleaning is a process of fixing or removing incorrect, corrupted, incorrectly formatted, duplicate, or incomplete data within dataset. When combining a multiple data sources, there are more opportunities for data to be a duplicated or mislabeled. If data is be incorrect, outcomes and algorithms are be unreliable, even though they may look correct. There is no one absolute way to be prescribe an exact steps in the data cleaning process because a processes will vary from a dataset to dataset. But it is crucial to be establish a template for a data cleaning process.
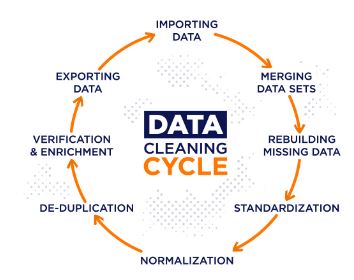
What is difference between the data cleaning and data transformation?
Data cleaning is a process that removes a data that does not belong in dataset. Data transformation is a process of converting data from one format or structure into the another. Transformation processes can also be referred to as a data wrangling, or data munging, transforming and mapping data from a one “raw” data form into the another format for a warehousing and analyzing. This article focuses on a processes of cleaning that data.
How to clean data?
While techniques used for a data cleaning may vary according to types of data are company stores, can follow these basic steps to a map out a framework for an organization.
Step 1: Remove duplicate or irrelevant observations:
Remove the unwanted observations from a dataset, including duplicate observations or an irrelevant observations. Duplicate observations are will happen most often during data collection. When combine a data sets from the multiple places, scrape data, or receive data from clients or multiple departments, there are opportunities to create a duplicate data. Deduplication is one of largest areas to be considered in this process. Irrelevant observations are when notice observations that do not fit into a specific problem and are trying to analyze. For example, if need to analyze a data regarding millennial customers, but a dataset includes the older generations, might remove those irrelevant observations. This can make a analysis more efficient and minimize distraction from a primary target—as well as creating a more manageable and more performant dataset.
Step 2: Fix structural errors:
Structural errors are when measure or a transfer data and notice the strange naming conventions, typos, or incorrect capitalization. These inconsistencies can cause a mislabeled categories or classes. For example, may find “N/A” and “Not Applicable” both appear, but they can should be analyzed as a same category.
Step 3: Filter unwanted outliers:
Often, there will be a one-off observations where, at glance, they do not appear to fit within a data are analyzing. If have a legitimate reason to remove a outlier, like a improper data-entry, doing so will help performance of the data are working with. However, sometimes it is the appearance of an outlier that will prove the theory are working on. Remember: just because outlier exists, doesn’t mean it is incorrect. This step is needed to find the validity of that number. If outlier proves to be an irrelevant for the analysis or is a mistake, consider removing it.
Step 4: Handle a missing data:
Can’t ignore a missing data because many algorithms will not be accept missing values. There are couple of ways to deal with a missing data. Neither is an optimal, but both can be a considered.
- 1.As first option, can drop the observations that have a missing values, but doing this will drop or lose information, so be mindful of this before can remove it.
- 2.As second option, can input are missing values based on the other observations; again, there is an opportunity to lose of integrity the data because may be an operating from the assumptions and not an actual observations.
- 3.As third option, might alter way the data is used to an effectively navigate null values.
Step 5: Validate and QA:
At end of a data cleaning process, should be able to answer questions as part of a basic validation:
Does a data make sense?
- Does a data follow appropriate rules for its field?
- Does it prove or disprove the working theory, or bring any insight to light?
- Can find trends in a data to help form next theory?
- If not, is that because of data quality problem ?
- False conclusions because of an incorrect or “dirty” data can inform a poor business strategy and decision-making. False conclusions can lead to embarrassing moment in the reporting meeting when can realize a data doesn’t stand up to scrutiny. Before get there, it is important to create a culture of quality data in an organization. To do this, should document a tools are might use to create this culture and what data quality means .
5 characteristics of a quality data:
1.Validity: The degree to which a data conforms to explained business rules or constraints.
2.Accuracy: Ensure a data is close to true values.
3.Completeness: The degree to which all the required data is known.
4.Consistency: Ensure a data is consistent within a same dataset and/or across the multiple data sets.
5.Uniformit:The degree to which a data is specified using same unit of measure.
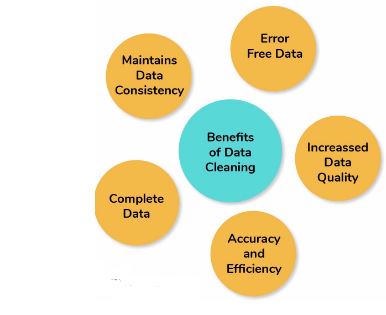
Advantages and benefits of data cleaning
Having a clean data will ultimately increase an overall productivity and allow for a highest quality information in a decision-making. Benefits include:
- Removal of errors when a multiple sources of a data are at play.
- A Fewer errors are make for happier clients and a less-frustrated employees.
- Ability to map various functions and what is data is intended to do.
- Monitoring the errors and better reporting to see where an errors are coming from, making it simpler to fix incorrect or corrupt data for future applications.
- Using a tools for data cleaning will make for the more efficient business practices and a quicker decision-making.
Conclusion
Using data scrubbing tool can save a database administrator significant amount of time by helping the analysts or administrators start their analyses faster and have more confidence in a data. Understanding a data quality and the tools are need to create, manage, and transform data is an important step toward making an efficient and effective business decisions. This crucial process are will further develop a data culture in an organization.