
- Difference between Waterfall approach and Agile approach
- CCIE Certification Cost in India
- What is IOT? | Know about IOT Application
- How to install Jenkins on Ubuntu? : A Complete Guide
- What is AWS Instance Types? : A Complete Guide
- VMware Site Recovery Manager : Know all about it
- What is Big Engineering? | Know about the salary
- What is Data Model in Salesforce ?
- Splunk architecture| Know from the basics [ OverView ]
- What is Azure Arc? | Integration Guide | A Complete Guide with Best Practices
- Introduction To Docker Networking: Advantages and Working | Everything You Need to Know
- Introduction to Azure ASR-enabled servers | All you need to know [ OverView ]
- Create Alarms in Amazon CloudWatch | Integration Guide | A Complete Guide with Best Practices
- What’s AWS VPC? Amazon Virtual Private Cloud Explained | A Complete Guide with Best Practices
- What Makes the Difference between Containers Vs Virtual Machines | All you need to know [ OverView ]
- What is a CDN? | How Do Content Delivery Networks Work | A Complete Guide with Best Practices
- Top Real World Applications of Cloud Computing | A Complete Guide with Best Practices
- What to Expect AWS Reinvent Reinforces the Growth of Cloud Computing|All you need to know [ OverView ]
- What is Cloud Computing Technology with SalesForce Integration | How its Work [ OverView ]
- Kubernetes vs Docker Swarm | What’s the Difference and Which Should You Learn?
- Big Data vs Data Warehouse | Know Their Differences and Which Should You Learn?
- Public Cloud vs Private Cloud | Know Their Differences and Which Should You Learn?
- Red Hat Certification Path: A Complete Guide For Beginners with Best Practices
- An Overview of AWS SDK and Toolkit | A Complete Guide with Best Practices
- An Overview of MuleSoft Anypoint | Benefits and Special Features | A Definitive Guide with Best Practices
- What is Amazon Elastic Load Balancer? : Benefits and Special Features with REAL-TIME Examples
- What is AWS Console ? : A Complete Guide with Best Practices
- Microsoft Azure Application Gateway | Step-By-Step Process with REAL-TIME Examples
- A Definitive Guide for Azure Automation | Benefits and Special Features
- Azure ExpressRoute | Everything You Need to Know | Expert’s Top Picks
- What is Hybrid Cloud? | Everything You Need to Know | Expert’s Top Picks
- A Complete Citrix Certification Path | A Complete Guide For Beginners [ OverView ]
- What is Azure Active Directory B2C ? : Step-By-Step Process with REAL-TIME Examples
- What is Azure DNS ? Azure DNS – Azure Domain Name System | REAL-TIME Examples
- Top AWS Statistics | Everything You Need to Know | Expert’s Top Picks
- Docker Swarm Architecture | Everything You Need to Know [ OverView ]
- What is Dell Boomi? | Everything You Need to Know [ OverView ]
- Cloud Architect Salary in India | All you need to know [ For Freshers and Experience ]
- What Is Multitenancy ? : Characteristics , Features , Benefits | All you need to know [ OverView ]
- What Is the Recommended List of AWS Whitepapers? | Expert’s Top Picks
- OSCP vs CEH | Difference You Should Know
- Openshift vs Kubernetes | Difference You Should Know
- AWS Cloud Practitioner and Required Skills | Expert’s Top Picks
- CRISC Certification and Benefits | A Complete Guide with Best Practices
- Kali vs Parrot | Difference You Should Know
- How to Install Docker on Ubuntu | Comprehensive Guide
- AWS Certification Cost and Types of Exams [ Job & Future ]
- What is the Average AWS Solutions Architect Salary?
- Reasons to Take up A Cloud Computing Certification
- What is Cloud Databases
- What is Cloud Computing Architecture?
- AWS vs Azure vs Google Cloud
- Top AWS Services
- Advantages and Disadvantages of Cloud Computing
- Cloud Computing 2020: An Analysis Of Cisco’s Cloud Index Survey, 2016
- What Are The Fundamental Microsoft Cloud Services That Are In Demand?
- What are the Issues in cloud computing?
- Top Important Cloud Computing Terms
- From Developer to AWS Cloud Specialist – The AWS Certification Learning Paths
- Why and How to Pursue a Career in AWS?
- The Top In-demand cloud skills for 2020
- Edge Computing Vs. Cloud Computing
- Top 10 Reasons to Learn AWS
- Cloud Computing Career Guide
- What does a AWS solution architect do?
- AWS Career Guide
- VMware vSphere best practices
- The AWS Engineer: Job Roles, Salaries And the Career Path
- What Is Microsoft Azure in Cloud Computing?
- How to Become an Azure Developer?
- Citrix Xenserver Vs Vmware vSphere
- Microsoft’s Project Olympus Delivers Cloud Hardware
- The Future of Cloud Computing
- Why Cloud Computing Is Essential to Your Organization?
- Amazon Web Services – WorkMail
- What is AWS?
- AWS Vs OpenStack
- AWS Certification Path
- AWS ElasticSearch
- AWS EC2 Instance Types
- Microsoft Azure Portal
- AWS Vs Azure
- Amazon Web Services WorkSpaces
- What is AWS Management Console?
- Difference between Waterfall approach and Agile approach
- CCIE Certification Cost in India
- What is IOT? | Know about IOT Application
- How to install Jenkins on Ubuntu? : A Complete Guide
- What is AWS Instance Types? : A Complete Guide
- VMware Site Recovery Manager : Know all about it
- What is Big Engineering? | Know about the salary
- What is Data Model in Salesforce ?
- Splunk architecture| Know from the basics [ OverView ]
- What is Azure Arc? | Integration Guide | A Complete Guide with Best Practices
- Introduction To Docker Networking: Advantages and Working | Everything You Need to Know
- Introduction to Azure ASR-enabled servers | All you need to know [ OverView ]
- Create Alarms in Amazon CloudWatch | Integration Guide | A Complete Guide with Best Practices
- What’s AWS VPC? Amazon Virtual Private Cloud Explained | A Complete Guide with Best Practices
- What Makes the Difference between Containers Vs Virtual Machines | All you need to know [ OverView ]
- What is a CDN? | How Do Content Delivery Networks Work | A Complete Guide with Best Practices
- Top Real World Applications of Cloud Computing | A Complete Guide with Best Practices
- What to Expect AWS Reinvent Reinforces the Growth of Cloud Computing|All you need to know [ OverView ]
- What is Cloud Computing Technology with SalesForce Integration | How its Work [ OverView ]
- Kubernetes vs Docker Swarm | What’s the Difference and Which Should You Learn?
- Big Data vs Data Warehouse | Know Their Differences and Which Should You Learn?
- Public Cloud vs Private Cloud | Know Their Differences and Which Should You Learn?
- Red Hat Certification Path: A Complete Guide For Beginners with Best Practices
- An Overview of AWS SDK and Toolkit | A Complete Guide with Best Practices
- An Overview of MuleSoft Anypoint | Benefits and Special Features | A Definitive Guide with Best Practices
- What is Amazon Elastic Load Balancer? : Benefits and Special Features with REAL-TIME Examples
- What is AWS Console ? : A Complete Guide with Best Practices
- Microsoft Azure Application Gateway | Step-By-Step Process with REAL-TIME Examples
- A Definitive Guide for Azure Automation | Benefits and Special Features
- Azure ExpressRoute | Everything You Need to Know | Expert’s Top Picks
- What is Hybrid Cloud? | Everything You Need to Know | Expert’s Top Picks
- A Complete Citrix Certification Path | A Complete Guide For Beginners [ OverView ]
- What is Azure Active Directory B2C ? : Step-By-Step Process with REAL-TIME Examples
- What is Azure DNS ? Azure DNS – Azure Domain Name System | REAL-TIME Examples
- Top AWS Statistics | Everything You Need to Know | Expert’s Top Picks
- Docker Swarm Architecture | Everything You Need to Know [ OverView ]
- What is Dell Boomi? | Everything You Need to Know [ OverView ]
- Cloud Architect Salary in India | All you need to know [ For Freshers and Experience ]
- What Is Multitenancy ? : Characteristics , Features , Benefits | All you need to know [ OverView ]
- What Is the Recommended List of AWS Whitepapers? | Expert’s Top Picks
- OSCP vs CEH | Difference You Should Know
- Openshift vs Kubernetes | Difference You Should Know
- AWS Cloud Practitioner and Required Skills | Expert’s Top Picks
- CRISC Certification and Benefits | A Complete Guide with Best Practices
- Kali vs Parrot | Difference You Should Know
- How to Install Docker on Ubuntu | Comprehensive Guide
- AWS Certification Cost and Types of Exams [ Job & Future ]
- What is the Average AWS Solutions Architect Salary?
- Reasons to Take up A Cloud Computing Certification
- What is Cloud Databases
- What is Cloud Computing Architecture?
- AWS vs Azure vs Google Cloud
- Top AWS Services
- Advantages and Disadvantages of Cloud Computing
- Cloud Computing 2020: An Analysis Of Cisco’s Cloud Index Survey, 2016
- What Are The Fundamental Microsoft Cloud Services That Are In Demand?
- What are the Issues in cloud computing?
- Top Important Cloud Computing Terms
- From Developer to AWS Cloud Specialist – The AWS Certification Learning Paths
- Why and How to Pursue a Career in AWS?
- The Top In-demand cloud skills for 2020
- Edge Computing Vs. Cloud Computing
- Top 10 Reasons to Learn AWS
- Cloud Computing Career Guide
- What does a AWS solution architect do?
- AWS Career Guide
- VMware vSphere best practices
- The AWS Engineer: Job Roles, Salaries And the Career Path
- What Is Microsoft Azure in Cloud Computing?
- How to Become an Azure Developer?
- Citrix Xenserver Vs Vmware vSphere
- Microsoft’s Project Olympus Delivers Cloud Hardware
- The Future of Cloud Computing
- Why Cloud Computing Is Essential to Your Organization?
- Amazon Web Services – WorkMail
- What is AWS?
- AWS Vs OpenStack
- AWS Certification Path
- AWS ElasticSearch
- AWS EC2 Instance Types
- Microsoft Azure Portal
- AWS Vs Azure
- Amazon Web Services WorkSpaces
- What is AWS Management Console?

Splunk architecture| Know from the basics [ OverView ]
Last updated on 28th Jan 2023, Artciles, Blog, Cloud Computing
- In this article you will get
- Different stages in Data Pipeline
- Splunk Components
- Splunk Architecture
- Conclusion
Different stages in Data Pipeline
The different stages in Data Pipeline:
- Data Input Stage
- Data Storage Stage
- Data Searching Stage
Data Input Stage:
At this point, we retrieve the original data source and transform it into 64k blocks. Included in the list of metadata keys are:
- Hostname.
- Source.
Source type of data:
Data Storage Stage:
This stage is carried out in two different phases, i.e
- Parsing
- Indexing
Parsing:During this process, the data is being analysed, manipulated, then analysed again by the Splunk software. When all the data sets are separated into their constituent events, we have reached the event processing phase. This parsing step includes the following actions.
- Lines are extracted from a continuous stream of data.
- Detects and records time stamps.
- Metadata and events are modified using a regular expression.
Indexing:At this point, Splunk software adds processed events to the index queue. The biggest advantage of utilising this is that the information will be readily visible to anybody conducting a search at that same moment.
Data Searching Stage:At this point, restrictions are put in place on who may see, use, and access the information. Knowledge objects, including as reports, event kinds, and alerts, may be created and saved by users inside the Splunk programme.
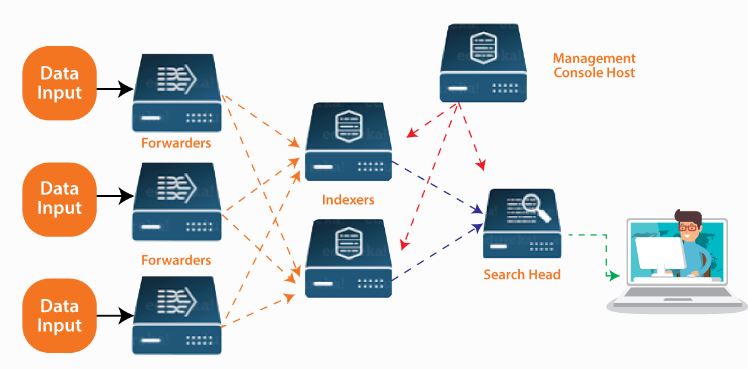
Splunk Components
Three components in Splunk are:
Splunk Forwarder:That is used to transmit information.
Splunk Indexer:It serves to both parse and index information.
Search Head:The user interface is the point at which one may do a search, perform an analysis, and generate a report.
Splunk Forwarder:
This component will be used to capture all of the log’s data. If you are trying to gather logs from a distant system then you need to utilise Splunk remote forwarders to perform the task.Splunk Forwarders may be used to capture real-time data so that the users can evaluate real-time data. For this to happen one need setup the Splunk Forwarders to deliver the data to Splunk Indexers in real-time.It requires extremely minimal processing power as compared to another typical monitoring tool. The scalability is another major favourable element.
We have two different types of forwarders:
- Splunk universal forwarder
- Splunk heavy forwarder
Splunk Indexer:This is another component that we may utilise for indexing and storing the data that is provided by the forwarders. The Splunk Indexer tool really allows the data to be turned into events and indexed so that it is easier for executing search operations quickly.If the data is flowing via Universal forwarder then Splunk Indexer will first parse the data and then Index it. Parsing the data will remove unnecessary info.If the data is flowing via Heavy forwarder then Splunk Indexer will just index the data.
As the Splunk indexer indexes the files then these files will contain the following:
- Compressed Raw data may be noticed.
- Index files, i.e. tsidx files.
One advantage of utilising Splunk Indexer is data replication. One doesn’t need to worry about the loss of data since Splunk stores several copies of the indexed data. This procedure is called Index replication or Indexer Clustering.
Splunk Search Head:
This stage really offers a graphical user interface where the user will be able to do various activities depending on his needs. By keying the keywords in the search box, the user will be able to retrieve the desired results depending on the term.Splunk Search Head may be installed on several servers and only we need to make sure that we activate Splunk Web services on the Splunk server so that the interactions are not interrupted.
We have two forms of Search heads, i.e.
- Search head
- Search peer
Search Head:This is the precise user interface where data can only be obtained based on keywords and is not indexed.
Search peer:One thing that can support both search results and indexing is search peer.
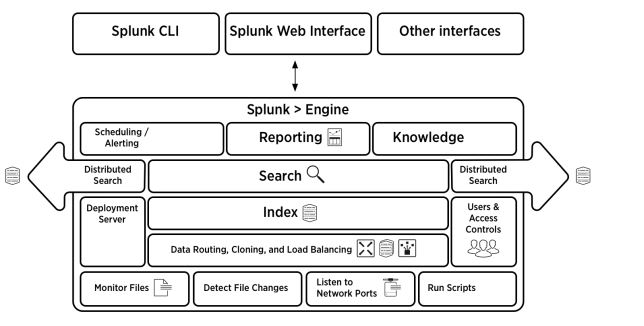
Splunk Architecture
Take a look at the illustration below for a condensed perspective of the many parts involved in the process and their functions:
- By running a few scripts, you may get data from many sources and set up this procedure to transfer data automatically.
- It is possible to keep track of all incoming files and identify modifications in real time.
- The forwarder can play a crucial role in data cloning, load balancing, and intelligent data routing. Before the data is sent to the indexer, all of these tasks can be completed.
- The complete setup, deployment, and policies, among other things, are managed by a deployment server.
- The data will eventually go to the indexer after being received. The information will be kept as events after it has been indexed. This makes carrying out any search activity very straightforward.
- They may be seen and examined using the graphical user interface when utilising the Search heads.
- With the help of the Search peers, one may produce reports, store searches, and do analysis using a dashboard view.
- You will be able to improve the current unstructured data using knowledge objects.
- Through the Splunk web interface, users may access the search heads and knowledge items. REST API connections are used for all conversations.
Conclusion
If you or your company is interested in Big Data analysis, Splunk is an excellent tool. If you need to evaluate a large amount of machine data, this is the tool for you. Data visualisation, report creation, data analysis, etc. are just some of the uses for this handy application. The IT staff will be able to make adjustments to their workflow based on the data and the comments provided.
To fully grasp the Splunk Architecture, it’s important to first get familiar with its individual parts. You may learn more about the function of this instrument and the key parts one should know by using these parts.