
- Most Popular SAP SuccessFactors Interview Questions and Answers
- [BEST & NEW] Business Management Interview Questions and Answers
- [ STEP-IN ] SAP BusinessObjects Cloud Interview Questions and Answers
- 80+ [REAL-TIME] Base Sas Interview Questions
- 100+ SAP Bodi Interview Questions & Answers
- [ TO GET HIRED ] PowerApps Interview Questions and Answers
- Must-Know [LATEST] Denodo Interview Questions and Answers
- [BEST & NEW] SAP Business One Interview Questions and Answers
- [FREQUENTLY ASK] SAP BI ABAP Interview Questions and Answers
- [BEST & NEW] Hyperion Planning Interview Questions and Answers
- 50+ Best SAP CS Interview Questions and Answers
- Get [LATEST] Boxi Interview Questions and Answers
- 50+ Best SAP E-Recruitment Interview Questions and Answers
- Get [LATEST] SAP SuccessFactors LMS Interview Questions and Answers
- 50+ Best SAP EHS Interview Questions and Answers
- SAP ECM Interview Questions and Answers [ TOP & MOST ASKED ]
- SAP FSCM Interview Questions and Answers [ FRESHERS ]
- Must-Know [LATEST] SIEBEL Business Analyst Interview Questions and Answers
- [FREQUENTLY ASK] Looker Interview Questions and Answers
- [BEST & NEW] SAP GTS Interview Questions and Answers
- 40+ REAL-TIME Anaplan Interview Questions and Answers
- [BEST & NEW] SAP BPC Interview Questions and Answers
- SAP Adobe Forms Interview Questions and Answers [SCENARIO-BASED ]
- Most Popular Alteryx Interview Questions and Answers [ SOLVED ]
- 50+ REAL-TIME SAP GRC Interview Questions and Answers
- SAP APO Interview Questions and Answers [ STEP-IN ]
- [FREQUENTLY ASK] SAP PM Interview Questions and Answers
- Top 30+ Splunk Admin Interview Questions and Answers
- 50+ Best Hyperion Financial Management Interview Questions and Answers
- Get SAP QM Interview Questions and Answers [BEST & NEW]
- Best SAS BI Interview Questions and Answers [LEARN NOW]
- [ TOP & MOST ASKED ] SAP ABAP on HANA Interview Questions and Answers
- Top SAP FIORI Interview Questions and Answers
- [50+] SAP FICA Interview Questions and Answers [ TO GET HIRED ]
- 30+ REAL-TIME Crystal Reports Interview Questions and Answers
- Browse [LATEST] SAP PI Interview Questions and Answers
- [ TOP & MOST ASKED ] SAP UI5 Interview Questions and Answers
- 30+ Best Jaspersoft Interview Questions [FREQUENTLY ASK]
- Business Objects Interview Questions and Answers
- SAS Interview Questions and Answers
- Splunk Interview Questions and Answers
- MSBI Developer Interview Questions and Answers
- SAP FICO Interview Questions and Answers
- SSAS Interview Questions and Answers
- SAP CRM Interview Questions and Answers
- SAP HR Interview Questions and Answers
- SAP Workflow Interview Questions and Answers
- SAP PP Interview Questions and Answers
- Dimensional Data Modeling Interview Questions and Answers
- SAP Bank Analyzer Interview Questions and Answers
- SAP ESS MSS Interview Questions and Answers
- SAP BI Interview Questions and Answers
- SAP WM Interview Questions and Answers
- SAP BI/BO Interview Questions and Answers
- Advanced SAS Interview Questions and Answers
- Appian Interview Questions and Answers
- SAP AFS Interview Questions and Answers
- SAP Retail Interview Questions and Answers
- SAP Security Interview Questions and Answers
- SAP COPA Interview Questions and Answers
- Pentaho Interview Questions and Answers
- SAP Material Management Interview Questions and Answers
- SAP BI/BW Interview Questions and Answers
- SAP SD Interview Questions and Answers
- SAP HANA Interview Questions and Answers
- Cognos Interview Questions and Answers
- QlikView Interview Questions and Answers
- MicroStrategy Interview Questions and Answers
- Business Analyst Interview Questions and Answers
- Qlik Sense Interview Questions and Answers
- Talend Interview Questions and Answers
- ETL Testing Interview Questions
- SSRS Interview Questions and Answers
- Tally Interview Questions and Answers
- OBIEE Interview Questions and Answer
- MSBI Interview Questions and Answers
- Power BI Interview Questions and Answers
- Tableau Interview Questions and Answers
- Most Popular SAP SuccessFactors Interview Questions and Answers
- [BEST & NEW] Business Management Interview Questions and Answers
- [ STEP-IN ] SAP BusinessObjects Cloud Interview Questions and Answers
- 80+ [REAL-TIME] Base Sas Interview Questions
- 100+ SAP Bodi Interview Questions & Answers
- [ TO GET HIRED ] PowerApps Interview Questions and Answers
- Must-Know [LATEST] Denodo Interview Questions and Answers
- [BEST & NEW] SAP Business One Interview Questions and Answers
- [FREQUENTLY ASK] SAP BI ABAP Interview Questions and Answers
- [BEST & NEW] Hyperion Planning Interview Questions and Answers
- 50+ Best SAP CS Interview Questions and Answers
- Get [LATEST] Boxi Interview Questions and Answers
- 50+ Best SAP E-Recruitment Interview Questions and Answers
- Get [LATEST] SAP SuccessFactors LMS Interview Questions and Answers
- 50+ Best SAP EHS Interview Questions and Answers
- SAP ECM Interview Questions and Answers [ TOP & MOST ASKED ]
- SAP FSCM Interview Questions and Answers [ FRESHERS ]
- Must-Know [LATEST] SIEBEL Business Analyst Interview Questions and Answers
- [FREQUENTLY ASK] Looker Interview Questions and Answers
- [BEST & NEW] SAP GTS Interview Questions and Answers
- 40+ REAL-TIME Anaplan Interview Questions and Answers
- [BEST & NEW] SAP BPC Interview Questions and Answers
- SAP Adobe Forms Interview Questions and Answers [SCENARIO-BASED ]
- Most Popular Alteryx Interview Questions and Answers [ SOLVED ]
- 50+ REAL-TIME SAP GRC Interview Questions and Answers
- SAP APO Interview Questions and Answers [ STEP-IN ]
- [FREQUENTLY ASK] SAP PM Interview Questions and Answers
- Top 30+ Splunk Admin Interview Questions and Answers
- 50+ Best Hyperion Financial Management Interview Questions and Answers
- Get SAP QM Interview Questions and Answers [BEST & NEW]
- Best SAS BI Interview Questions and Answers [LEARN NOW]
- [ TOP & MOST ASKED ] SAP ABAP on HANA Interview Questions and Answers
- Top SAP FIORI Interview Questions and Answers
- [50+] SAP FICA Interview Questions and Answers [ TO GET HIRED ]
- 30+ REAL-TIME Crystal Reports Interview Questions and Answers
- Browse [LATEST] SAP PI Interview Questions and Answers
- [ TOP & MOST ASKED ] SAP UI5 Interview Questions and Answers
- 30+ Best Jaspersoft Interview Questions [FREQUENTLY ASK]
- Business Objects Interview Questions and Answers
- SAS Interview Questions and Answers
- Splunk Interview Questions and Answers
- MSBI Developer Interview Questions and Answers
- SAP FICO Interview Questions and Answers
- SSAS Interview Questions and Answers
- SAP CRM Interview Questions and Answers
- SAP HR Interview Questions and Answers
- SAP Workflow Interview Questions and Answers
- SAP PP Interview Questions and Answers
- Dimensional Data Modeling Interview Questions and Answers
- SAP Bank Analyzer Interview Questions and Answers
- SAP ESS MSS Interview Questions and Answers
- SAP BI Interview Questions and Answers
- SAP WM Interview Questions and Answers
- SAP BI/BO Interview Questions and Answers
- Advanced SAS Interview Questions and Answers
- Appian Interview Questions and Answers
- SAP AFS Interview Questions and Answers
- SAP Retail Interview Questions and Answers
- SAP Security Interview Questions and Answers
- SAP COPA Interview Questions and Answers
- Pentaho Interview Questions and Answers
- SAP Material Management Interview Questions and Answers
- SAP BI/BW Interview Questions and Answers
- SAP SD Interview Questions and Answers
- SAP HANA Interview Questions and Answers
- Cognos Interview Questions and Answers
- QlikView Interview Questions and Answers
- MicroStrategy Interview Questions and Answers
- Business Analyst Interview Questions and Answers
- Qlik Sense Interview Questions and Answers
- Talend Interview Questions and Answers
- ETL Testing Interview Questions
- SSRS Interview Questions and Answers
- Tally Interview Questions and Answers
- OBIEE Interview Questions and Answer
- MSBI Interview Questions and Answers
- Power BI Interview Questions and Answers
- Tableau Interview Questions and Answers

Dimensional Data Modeling Interview Questions and Answers
Last updated on 14th Oct 2020, Blog, Business Analytics, Interview Question
In my previous article i have explained about the data modeling techniques with its real life examples.In this article i would like to give you an idea about Data Modeling Interview Questions. I have written so many articles which gives you the idea about different SQL interview questions which are important for the users. I need to explain the users about Data Modeling Interview Questions with answers in this article.Now a days data modeling becomes the backbone of any new technology like Business Intelligence.In this article i will give some most important Data Modeling Interview Questions with its answers so that it’s easy for user to face the interview.
1. What do you understand by Data Modelling?
Ans:
Data Modelling is the diagrammatic representation showing how the entities are related to each other. It is the initial step towards database design. We first create the conceptual model, then the logical model and finally move to the physical model.Generally, the data models are created in the data analysis & design phase of the software development life cycle.
2. Explain your understanding of different data models?
Ans:
There are three types of data models:
- conceptual
- logical
- physical
The level of complexity and detail increases from conceptual to logical to a physical data model.The conceptual model shows a very basic high level of design while the physical data model shows a very detailed view of design.
- Conceptual Model will be just portraying entity names and entity relationships. Figure 1 shown in the later part of this article depicts a conceptual model.
- The Logical Model will be showing entity names, entity relationships, attributes, primary keys and foreign keys in each entity. Figure 2 shown inside question#4 in this article depicts a logical model.
- The Physical Data Model will be showing primary keys, foreign keys, table names, column names and column data types. This view actually elaborates how the model will be actually implemented in the database.
3. Throw some light on your experience in Data Modelling with respect to projects you have worked on till date?
Ans:
This was the very first question in one of my Data Modelling interviews. So, before you step into the interview discussion, you should have a very clear picture of how data modeling fits into the assignments you have worked upon.
I have worked on a project for a health insurance provider company where we have interfaces built in Informatics that transforms and processes the data fetched from Facets database and sends out useful information to vendors.
Note: Facets is an end to end solution to manage all the information for the healthcare industry. The facets database in my project was created with SQL server 2012.
We had different entities that were linked together. These entities were subscriber, member, healthcare provider, claim, bill, enrollment, group, eligibility, plan/product, commission, capitation, etc.
4. What are the different design schemas in Data Modelling? Explain with the example?
Ans:
There are two different kinds of schema in data modeling:
- Star Schema
- Snowflake Schema
Now, I will be explaining each of these schemas one by one.
The simplest of the schemas is the star schema where we have a fact table in the center that references multiple dimension tables around it. All the dimension tables are connected to the fact table. The primary key in all dimension tables acts as a foreign key in the fact table.
5. Which scheme did you use in your project & why?
Ans:
The star schema is quite simple, flexible and it is in de-normalized form.
In a snowflake schema, the level of normalization increases. The fact table here remains the same as in the star schema. However, the dimension tables are normalized. Due to several layers of dimension tables, it looks like a snowflake and thus it is named as snowflake schema.
6. Which schema is better – star or snowflake?
Ans:
Since the star schema is in de-normalized form, you require fewer joins for a query. The query is simple and runs faster in a star schema. Coming to the snowflake schema, since it is in normalized form, it will require a number of joins as compared to a star schema, the query will be complex and execution will be slower than star schema.Another significant difference between these two schemas is that snowflake schema does not contain redundant data and thus it is easy to maintain. On the contrary, star schema has a high level of redundancy and thus it is difficult to maintain.Now, which one to choose for your project? If the purpose of your project is to do more dimension analysis, you should go for a snowflake schema.
7. What do you understand by dimension and attribute?
Ans:
Dimensions represent qualitative data. For Example, plan, product, class are all dimensions.A dimension table contains descriptive or textual attributes. For Example, the product category & product name are the attributes of the product dimension.
8. What is a fact a fact table?
Ans:
Facts represent quantitative data.
For Example: the net amount due is a fact. A fact table contains numerical data and foreign keys from related dimensional tables.
9. What are the different types of dimensions you have come across? Explain each of them in detail with an example?
Ans:
There are typically five types of dimensions:
- Conformed dimensions: A Dimension that is utilized as a part of different areas is called a conformed dimension. It might be utilized with different fact tables in a single database or over numerous data marts/warehouses.
- Junk Dimension: It is a dimension table consisting of attributes that don’t have a place in the fact table or in any of the current dimension tables. Generally, these are properties like flags or indicators.
- Role-Playing Dimension: These are the dimensions that are utilized for multiple purposes in the same database.
- For Example: a date dimension can be used for Date of Claim, Billing data Plan Term date. So, such a dimension will be called a Role-playing dimension. The primary key of the Date dimension will be associated with multiple foreign keys in the fact table.
- Slowly Changing Dimension (SCD): These are most important amongst all the dimensions. These are the dimensions where attribute values vary with time. Below are the various types of SCDs
- Type-0: These are the dimensions where attribute value remains steady with time. For Example, Subscribers DOB is a type-0 SCD because it will always remain the same irrespective of the time.
- Type-1: These are the dimensions where the previous value of the attribute is replaced by the current value. No history is maintained in the Type-1 dimension. For Example, Subscribers address (where the business requires to keep the only current address of subscriber) can be a Type-1 dimension.
- Type-2: These are the dimensions where unlimited history is preserved. For Example, Subscribers address (where the business requires to keep a record of all the previous addresses of the subscriber). In this case, multiple rows for a subscriber will be inserted in the table with his/her different addresses. There will be some column(s) that will identify the current address. For Example, Start date and End date. The row where End datevalue will be blank would contain the subscribers current address and all other rows will be having previous addresses of the subscriber.
- Type-3: These are the type of dimensions where limited history is preserved. And we use an additional column to maintain the history. For Example, Subscribers address (where the business requires to keep a record of current & just one previous address). In this case, we can dissolve the address column into two different columns – current address and previous address. So, instead of having multiple rows, we will be having just one-row showing current as well as the previous address of the subscriber.
- Type-4: In this type of dimension, the historical data is preserved in a separate table. The main dimension table holds only the current data. For Example, the main dimension table will have only one row per subscriber holding its current address. All other previous addresses of the subscriber will be kept in the separate history table. This type of dimension is hardly ever used.
- Degenerated Dimension: A degenerated dimension is a dimension that is not a fact but presents in the fact table as a primary key. It does not have its own dimension table. We can also call it a single attribute dimension table.
But, instead of keeping it separately in a dimension table and putting an additional join, we put this attribute in the fact table directly as a key. Since it does not have its own dimension table, it can never act as a foreign key in the fact table.
10. Give your idea regarding factless fact? And why do we use it?
Ans:
Factless fact table is a fact table that contains no fact measure in it. It has only the dimension keys in it.
At times, certain situations may arise in the business where you need to have a factless fact table.
For Example, suppose you are maintaining an employee attendance record system, you can have a factless fact table having three keys.
- Employee_ID
- Department_ID
- Time_ID
You can see that the above table does not contain any measure. Now, if you want to answer the below question, you can do easily using the above single factless fact table rather than having two separate fact tables:
How many employees of a particular department were present on a particular day:
So, the factless fact table offers flexibility to the design.
11. Distinguish between OLTP and OLAP?
Ans:
OLTP stands for the Online Transaction Processing System &OLAP stands for the Online Analytical Processing System. OLTP maintains the transactional data of the business is highly normalized generally. On the contrary, OLAP is for analysis and reporting purposes & it is in denormalized form.
This difference between OLAP and OLTP also gives you the way to choose the design of a schema. If your system is OLTP, you should go with star schema design and if your system is OLAP, you should go with snowflake schema.
12. What do you understand by data mart?
Ans:
Data marts are for the most part intended for a solitary branch of business. They are designed for the individual departments.
For Example, I used to work for a health insurance provider company that had different departments in it like Finance, Reporting, Sales and so forth.
We had a data warehouse that was holding the information pertaining to all these departments and then we have few data marts built on top of this data warehouse. These DataMart were specific to each department. In simple words, you can say that a DataMart is a subset of a data warehouse.
13. What are the different types of measures?
Ans:
We have three types of measures, namely:
- Non- additive measures
- Semi- additive measures
- Additive measures
- Non-additive measures are the ones on top of which no aggregation function can be applied. For Example, a ratio or a percentage column; a flag or an indicator column present in fact table holding values like Y/N, etc. is a non-additive measure.
- Semi- additive measures are the ones on top of which some (but not all) aggregation functions can be applied. For Example, fee rate or account balance.
- Additive measures are the ones on top of which all aggregation functions can be applied. For Example, units purchased.
Subscribe For Free Demo
Error: Contact form not found.
14. What is a Surrogate key? How is it different from a primary key?
Ans:
Surrogate Key is a unique identifier or a system-generated sequence number key that can act as a primary key. It can be a column or a combination of columns. Unlike a primary key, it is not picked up from the existing application data fields.
15. Is this true that all databases should be in 3NF?
Ans:
It is not mandatory for a database to be in 3NF. However, if your purpose is the easy maintenance of data, less redundancy, and efficient access then you should go with a denormalized database.
16. Have you ever come across the scenario of recursive relationships? If yes, how did you handle it?
Ans:
A recursive relationship occurs in the case where an entity is related to itself. Yes, I have come across such a scenario.
Talking about the healthcare domain, it is a possibility that a healthcare provider (say, a doctor) is a patient to any other health care provider. Because, if the doctor himself falls ill and needs surgery, he will have to visit some other doctor for getting the surgical treatment.
So, in this case, the entity – health care provider is related to itself. A foreign key to the health insurance provider’s number will have to be present in each member’s (patient) record.
17. List out a few common mistakes encountered during Data Modelling?
Ans:
Few common mistakes encountered during Data Modelling are:
- Building massive data models: Large data models are likely to have more design faults. Try to restrict your data model to not more than 200 tables.
- Lack of purpose: If you do not know what your business solution is intended for, you might come up with an incorrect data model. So having clarity on the business purpose is very important to come up with the right data model.
- Inappropriate use of surrogate keys: Surrogate keys should not be used unnecessarily. Use a surrogate key only when the natural key cannot serve the purpose of a primary key.
- Unnecessary denormalization: Don’t denormalize until and unless you have a solid & clear business reason to do so because denormalization creates redundant data which is difficult to maintain.
18. What is the number of child tables that can be created out from a single parent table?
Ans:
The number of child tables that can be created out of the single parent table is equal to the number of fields/columns in the parent table that are non-keys.
19. Employee health details are hidden from his employer by the health care provider. Which level of data hiding is this? Conceptual, physical or external?
Ans:
This is the scenario of an external level of data hiding.
20. What is the form of a fact table vs dimension table?
Ans:
Generally, the fact table is in normalized form and the dimension table is in de-normalized form.
Subscribe For Free Demo
SUBSCRIBE
21. What particulars would you need to come up with a conceptual model in a healthcare domain project?
Ans:
For a health care project, below details would suffice the requirement to design a basic conceptual model.
Different categories of health care plans and products:
- Type of subscription (group or individual).
- Set of health care providers.
- Claim and billing process overview.
22. Tricky one: If a unique constraint is applied to a column then will it throw an error if you try to insert two nulls into it?
Ans:
No, it will not throw any error in this case because a null value is unequal to another null value. So, more than one null will be inserted in the column without any error.
23. Can you quote an example of a subtype and supertype entity?
Ans:
Yes, let’s say we have these different entities: vehicle, car, bike, economy car, family car, sports car.
Here, a vehicle is a super-type entity. Car and bike are its subtype entities. Furthermore, economy cars, sports cars, and family cars are subtype entities of its super-type entity- car.
A super-type entity is the one that is at a higher level. Subtype entities are ones that are grouped together on the basis of certain characteristics. For Example, all bikes are two-wheelers and all cars are four-wheelers. And since both are vehicles, so their super-type entity is a vehicle.
24. What is the significance of metadata?
Ans:
Metadata is data about data. It tells you what kind of data is actually stored in the system, what is its purpose and for whom it is intended.
25. What is the difference between star flake and snowflake schema?
Ans:
Star Schema:
Well in star schema you just enter your desired facts and all the primary keys of your dimensional tables in the Fact table. And fact tables primarily are the union of its all dimension table key. In star schema dimensional tables are usually not in BCNF form.
SnowFlake:
It’s almost like a star schema but in this our dimension tables are in 3rd NF, so more dimension tables. And these dimension tables are linked by primary, foreign key relation.
26. What is data sparsity and how does it affect aggregation?
Ans:
Data sparsity is the term used for how much data we have for a particular dimension/entity of the model.
It affects aggregation depending on how deep the combination of members of the sparse dimension make up. If the combination is a lot and those combinations do not have any factual data then creating space to store those aggregations will be a waste as a result, the database will become huge.
27. What is the difference between hashed file stage and sequential file stage in relation to DataStage Server?
Ans:
- In data stage server jobs,can we use sequential file stage for a lookup instead of hashed file stage.If yes ,then what’s the advantage of a Hashed File stage over sequential file stage
- search is faster in hash files as you can directly get the address of record directly by hash algorithm as records are stored like that but in case of sequential file u must compare all the records.
28. When should you consider denormalization?
Ans:
Denationalization is used when there are a lot of tables involved in retrieving data. Denormalization is done in dimensional modelling used to construct a data warehouse. This is not usually done for databases of transnational systems.
29. What is ERD?
Ans:
Data models are tools used in analysis to describe the data requirements and assumptions in the system from a top-down perspective. They also set the stage for the design of databases later on in the SDLC.
30. What is the third normal form?
Ans:
An entity is in the third normal form if it is in the second normal form and all of its attributes are not transitively dependent on the primary key. Transitive dependence means that descriptor key attributes depend not only on the whole primary key, but also on other descriptor key attributes that, in turn, depend on the primary key. In SQL terms, the third normal form means that no column within a table is dependent on a descriptor column that, in turn, depends on the primary key.
For 3NF, first, the table must be in 2NF, plus, we want to make sure that the non-key fields are dependent upon ONLY the PK, and not other non-key fields for its existence. This is very similar to 2NF, except that now you are comparing the non-key fields to OTHER non-key fields. After all, we know that the relationship to the PK is good, because we established that in 2NF.
Get Dimensional Data Modeling Training from Real Time Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Explore Curriculum
31. What is an artificial (derived) primary key? When should it be used?
Ans:
Using a name as the primary key violates the principle of stability. The social security number might be a valid choice, but a foreign employee might not have a social security number. This is a case where a derived, rather than a natural, primary key is appropriate. A derived key is an artificial key that you create. A natural key is one that is already part of the database.
32. What is the second normal form?
Ans:
An entity is in the second normal form if all of its attributes depend on the whole (primary) key. In relational terms, every column in a table must be functionally dependent on the whole primary key of that table. Functional dependency indicates that a link exists between the values in two different columns.
If the value of an attribute depends on a column, the value of the attribute must change if the value in the column changes. The attribute is a function of the column. The following explanations make this more specific:
If the table has a one-column primary key, the attribute must depend on that key.
If the table has a composite primary key, the attribute must depend on the values in all its columns taken as a whole, not on one or some of them.
If the attribute also depends on other columns, they must be columns of a candidate key; that is, columns that are unique in every row.
If you do not convert your model to the second normal form, you risk data redundancy and difficulty in changing data. To convert first-normal-form tables to second-normal-form tables, remove columns that are not dependent on the primary key.
33. What is Enterprise Data Modeling?
Ans:
The development of a common consistent view and understanding of data elements and their relationships across the enterprise is referred to as Enterprise Data Modeling. This type of data modeling provides access to information scattered throughout an enterprise under the control of different divisions or departments with different databases and data models.
Enterprise Data Modeling is sometimes called as a global business model and the entire information about the enterprise would be captured in the form of entities.
34. Logical V/s Physical Data Model?
Ans:
When a data modeler works with the client, his title may be a logical data modeler or a physical data modeler or a combination of both. A logical data modeler designs the data model to suit business requirements, creates and maintains the lookup data, compares the versions of the data model, maintains change log, generates reports from the data model and whereas a physical data modeler has to know about the source and target databases properties.
A physical data modeler should know the technical-know-how to create data models from existing databases and to tune the data models with referential integrity, alternate keys, indexes and how to match indexes to SQL code. It would be good if the physical data modeler knows about replication, clustering and so on.

Get Dimensional Data Modeling Training from Real Time Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
35. Relational vs Dimensional?
Ans:
Relational Data Modeling is used in OLTP systems which are transaction oriented and Dimensional Data Modeling is used in OLAP systems which are analytical based. In a data warehouse environment, staging area is designed on OLTP concepts, since data has to be normalized, cleansed and profiled before loaded into a data warehouse or data mart. In OLTP environments, lookups are stored as independent tables in detail whereas these independent tables are merged as a single dimension in an OLAP environment like a data warehouse.
| Relational Data Modeling | Dimensional Data Modeling |
|---|---|
| Data is stored in RDBMS | Data is stored in RDBMS or Multidimensional databases |
| Tables are units of storage | Cubes are units of storage |
| Data is normalized and used for OLTP. Optimized for OLTP processing | Data is denormalized and used in data warehouses and data mart. Optimized for OLAP |
| Several tables and chains of relationships among them | Few tables and fact tables are connected to dimensional tables |
| Volatile(several updates) and time variant | Non volatile and time-invariant |
| Detailed level of transactional data |
36. What is a Data Modeling Development Cycle?
Ans:
- Gathering Business Requirements – First Phase: Data Modelers have to interact with business analysts to get the functional requirements and with end users to find out the reporting needs.
- Conceptual Data Modeling(CDM) – Second Phase: This data model includes all major entities, relationships and it will not contain much detail about attributes and is often used in the INITIAL PLANNING PHASE.
- Logical Data Modeling(LDM) – Third Phase: This is the actual implementation of a conceptual model in a logical data model. A logical data model is the version of the model that represents all of the business requirements of an organization.
- Physical Data Modeling(PDM) – Fourth Phase: This is a complete model that includes all required tables, columns, relationship, database properties for the physical implementation of the database.
- Database – Fifth Phase: DBAs instruct the data modeling tool to create SQL code from physical data model. Then the SQL code is executed on the server to create databases.
Standardization Needs and Modeling data:
Several data modelers may work on the different subject areas of a data model and all data modelers should use the same naming convention, writing definitions and business rules.
Nowadays, business to business transactions(B2B) are quite common, and standardization helps in understanding the business in a better way. Inconsistency across column names and definition would create chaos across the business.
For example: when a data warehouse is designed, it may get data from several source systems and each source may have its own names, data types etc. These anomalies can be eliminated if a proper standardization is maintained across the organization.
37. What is a Table?
Ans:
A table consists of data stored in rows and columns. Columns, also known as fields, show data in vertical alignment. Rows, also called a record or tuple, represent datas horizontal alignment.
38. What is Normalization?
Ans:
Database normalization is the process of designing the database in such a way that it reduces data redundancy without sacrificing integrity.
39. What Does a Data Modeler Use Normalization For?
Ans:
The purposes of normalization are:
- Remove useless or redundant data
- Reduce data complexity
- Ensure relationships between the tables in addition to the data residing in the tables
- Ensure data dependencies and that the data is stored logically.
40. What Are the Critical Relationship Types Found in a Data Model? Describe Them:
Ans:
The main relationship types are:
- Identifying: A relationship line normally connects parent and child tables. But if a child table’s reference column is part of the table’s primary key, the tables are connected by a thick line, signifying an identifying relationship.
- Non-identifying: If a child table’s reference column is NOT a part of the table’s primary key, the tables are connected by a dotted line, signifying a no-identifying relationship.
- Self-recursive: A recursive relationship is a standalone column in a table connected to the primary key in the same table.
41. What is an Enterprise Data Model?
Ans:
This is a data model that consists of all the entries required by an enterprise.
- Data Scientist Master’s Program
- In Collaboration with IBM EXPLORE COURSE
- Intermediate Interview Questions.
42. What Are the Most Common Errors You Can Potentially Face in Data Modeling?
Ans:
These are the errors most likely encountered during data modeling:
- Building overly broad data models: If tables are run higher than 200, the data model becomes increasingly complex, increasing the likelihood of failure
- Unnecessary surrogate keys: Surrogate keys must only be used when the natural key cannot fulfill the role of a primary key
- The purpose is missing: Situations may arise where the user has no clue about the business mission or goal. Its difficult, if not impossible, to create a specific business model if the data modeler doesn’t have a workable understanding of the company’s business model
- Inappropriate denormalization: Users shouldnt use this tactic unless there is an excellent reason to do so. Denormalization improves read performance, but it creates redundant data, which is a challenge to maintain.
43. What is a Slowly Changing Dimension?
Ans:
These are dimensions used to manage both historical data and current data in data-warehousing. There are four different types of slowly changing dimensions: SCD Type 0 through SCD Type 3.
44. What is Granularity?
Ans:
Granularity represents the level of information stored in a table. Granularity is defined as high or low. High granularity data contains transaction-level data. Low granularity has low-level information only, such as that found in fact tables.
45. What Are Subtype and Supertype Entities?
Ans:
Entities can be broken down into several sub-entities, or grouped by specific features. Each sub-entity has relevant attributes and is called a subtype entity. Attributes common to every entity are placed in a higher or super level entity, which is why they are called supertype entities.
46. What’s the Difference Between Forward and Reverse Engineering, in the Context of Data Models?
Ans:
Forward engineering is a process where Data Definition Language (DDL) scripts are generated from the data model itself. DDL scripts can be used to create databases. Reverse Engineering creates data models from a database or scripts. Some data modeling tools have options that connect with the database, allowing the user to engineer a database into a data model.
47. What’s a Conformed Dimension?
Ans:
If a dimension is confirmed, it’s attached to at least two fact tables.
48. Why Are NoSQL Databases More Useful than Relational Databases?
Ans:
NoSQL databases have the following advantages:
- They can store structured, semi-structured, or unstructured data
- They have a dynamic schema, which means they can evolve and change as quickly as needed
- NoSQL databases have sharding, the process of splitting up and distributing data to smaller databases for faster access
- They offer failover and better recovery options thanks to the replication
- It’s easily scalable, growing or shrinking as necessary.
49. What’s a Junk Dimension?
Ans:
This is a grouping of low-cardinality attributes like indicators and flags, removed from other tables, and subsequently junk into an abstract dimension table. They are often used to initiate Rapidly Changing Dimensions within data warehouses.
50. Name the possible type of a Data Model?
Ans:
It could be the physical data model and the logical data model, enterprise data model, conceptual data model, relational data model, OLTP data model etc.
Best Hands-on Practical Dimensional Data Modeling Course to Build Your Skills
Weekday / Weekend Batches
See Batch Details
51. What is contained by the logical data model?
Ans:
A logical data model contains entity, attributes, primary key, alternate key, Inversion keys, rule, definition, business relation etc.
- Learn SQL Server in the Easiest Way
- Learn from the videos
- Learn anytime anywhere
- Pocket-friendly mode of learning
- Complimentary eBook available
- Buy Self-learning at Discounted Price.
52. How will you differentiate a logical data model from logical data modeling?
Ans:
A logical data model is related to the business requirements and it is used for the actual implementation of the data. The approach that is used for creating a logical data model is called the logical data modeling.
53. What is an entity (Table)?
Ans:
A database is consisting of multiple rows and columns which is called a table together. Further, each column has a specific data type and based on conditions constraints are set of the columns.

Best Hands-on Practical Dimensional Data Modeling Course to Build Your Skills
Weekday / Weekend BatchesSee Batch Details54. What is an attribute (Column)?
Ans:
A Column is defined as the vertical alignment of data and information stored for that particular column.
55. What is a row?
Ans:
A row is the set of tuples, records, or it could be taken as the horizontal arrangement of the data.
56. What do you understand by the primary key constraint in a database?
Ans:
The primary key constraint is set on a column to avoid null values or duplicate values. In simple words, a column containing unique items can be defined as the primary key constraint. It could be the bank number, security number or more.
57. What do you know about foreign key constraints?
Ans:
The Primary key can be defined for the parent table and foreign key is set for the child table. The foreign key constraint always refers to the primary key constraint in the main table:
- SQL Server Training & Certification
- No cost for a Demo Class
- Industry Expert as your Trainer
- Available as per your schedule
- Customer Support Available
- Enrol For a Free Demo Class
- Advanced-Data Modeling Interview Questions.
58. Why is a composite word added before any key constraint?
Ans:
When the same constraint is enforced on multiple columns then the composite word is added before that particular key constraint.
59. Name a few popular relationships within a data model?
Ans:
These are identifying, non-identifying, and self-recursive relationships in a data model.
60. What do you mean by the identifying relationships in a data model?
Ans:
As you know the parent table and the child table both are connected together with a thin line. When the referenced column in a child table is a part of the primary key in the parent table then that relationship is drawn by a thick line and it is named as the identifying relationships in a data model.
61. Is there any non-identifying relationship too?
Ans:
In most of the cases, a parent table and the child table both are connected together with a thin line. When the referenced column in a child table is not a part of the primary key in the parent table then that relationship is drawn by a dotted line and it is named as the non-identifying relationships in a data model.
62. How will you define the cardinality in a data model?
Ans:
Cardinalities are used to define relationships and it could be one-to-one, one-to-many, or many-to-many etc. Higher the value of cardinality, there will be more unique values within a column.
63. What is a constraint? Why are constraints important for a database?
Ans:
This is a rule imposed on the data. A different type of constraints could be unique, null values, foreign keys, composite key or check constraint etc.
64. Define unique constraints for a database?
Ans:
This constraint is added to avoid duplicate values within a column.
65. Define the check constraint?
Ans:
A check constraint is useful to define the range of values within a column.
66. What is an index in a database?
Ans:
An Index is composed of a set of columns or a single column that is needed for fast retrieval of data.
67. What is the sequence?
Ans:
A sequence could be defined as the database object that is needed for the creation of a unique number.
68. What is the ETL process in data warehousing?
Ans:
ETL is Extract Transform Load. It is a process of fetching data from different sources, converting the data into a consistent and clean form and load into the data warehouse. Different tools are available in the market to perform ETL jobs.
69.What are Data Model ?
Ans:
When an enterprise logical data model is transformed to a physical data model, supertypes and subtypes may not be as is. i.e. the logical and physical structure of supertypes and subtypes may be entirely different. A data modeler has to change that according to the physical and reporting requirement.
When an enterprise logical data model is transformed to a physical data model, length of table names, column names etc may exceed the maximum number of the characters allowed by the database. So a data modeler has to manually edit that and change the physical names according to database or organizations standards.
One of the important things to note is the standardization of the data model. Since the same attribute may be present in several entities, the attribute names and data types should be standardized and a conformed dimension should be used to connect to the same attribute present in several tables.
Standard Abbreviation document is a must so that all data structure names would be consistent across the data model.
70. Explain the difference between data mining and data warehousing.
Ans:
Data warehousing is merely extracting data from different sources, cleaning the data and storing it in the warehouse. Whereas data mining aims to examine or explore the data using queries. These queries can be fired on the data warehouse. Exploring the data in data mining helps in reporting, planning strategies, finding meaningful patterns etc.
E.g: a data warehouse of a company stores all the relevant information of projects and employees. Using Data mining, one can use this data to generate different reports like profits generated etc.
Dimensional Data Modeling Sample Resumes! Download & Edit, Get Noticed by Top Employers!DOWNLOAD
71. What is an OLTP system and OLAP system?
Ans:
- OLTP: Online Transaction and Processing helps and manages applications based on transactions involving high volume of data. Typical examples of a transaction are commonly observed in Banks, Air tickets etc. Because OLTP uses client server architecture, it supports transactions to run across a network.
- OLAP: Online analytical processing performs analysis of business data and provides the ability to perform complex calculations on usually low volumes of data. OLAP helps the user gain an insight on the data coming from different sources (multi dimensional).
72. What is PDAP?
Ans:
A data cube stores data in a summarized version which helps in a faster analysis of data. The data is stored in such a way that it allows reporting easily.
using a data cube A user may want to analyze weekly, monthly performance of an employee. Here, month and week could be considered as the dimensions of the cube.
73. What is snowflake schema design in databases?
Ans:
A snowflake Schema in its simplest form is an arrangement of fact tables and dimension tables. The fact table is usually at the center surrounded by the dimension table. Normally in a snow flake schema the dimension tables are further broken down into more dimension tables.
E.g: Dimension tables include employee, projects and status. Status table can be further broken into status_weekly, status_monthly.
74. What is Data Modeling?
Ans:
1.Data Modeling is nothing but the database design technique which is useful to fetch different types of complex sql queries in DWH environment.
2.The Data Modeling technique is nothing but representation of Logical data model and physical data model according to the Business requirements.
3.Data Modeling is the most important Design technique which is used to support the users in data warehousing.
4.Data Modeling always uses two types of tables you can say it as facts and dimensions tables.
5.Facts tables are the tables which contain numerical values which can be aggregated and analyzed on fact values.Dimension defines hierarchies and description of fact values.
75. Explain Fact tables with example
Ans:
Fact table is central table found in star schema or snowflake schema which is surrounded by dimension tables.Fact table contains numeric values that are known as measurements.Fact table has two types of columns:
1.Facts
2.Foreign key of dimension tables.
Real Example :
Following is a fact table which contains all the primary keys of the dimensions table and added measures for ITEM,i.e.Product sold.
| ITEM KEY | Time key | Product key | Date key | Product Sold |
|---|---|---|---|---|
| 00001 | T001 | P001 | D001 | 100 |
| 00002 | T002 | P002 | D002 | 30 |
| 00003 | T003 | P003 | D003 | 15 |
The fact table contains the foreign keys,time dimensions,product dimension,customer dimension,measurement values.Following are some examples of common facts :
No units sold,Margin,Sales revenue and the dimension tables are customer,time and product e.t.c. which is used to analyse data.
76. What are different types of fact tables?( 100% asked Data Modeling Interview Questions )
Ans:
There are following 3 types of fact tables :
1.Additive :
Measures that can be added across any dimension
2.Non-additive:
Measures that can not be added across any dimension
3.Semi-additive:
Measures that can be added across some dimensions.
77. What are different types of data models?( 100% asked Data Modeling Interview Questions )
Ans:
There are two types of data model:
1.Logical Data Model
2.Physical data model
Logical Data Model:
1.The logical data model is nothing but the representation of your database in a logical way.
2.The logical data model is actually a representation of business requirements in a logical way.
3.The logical data model is the actual implementation and extension of a conceptual data model.
4.There are following different things used for creating logical data model:
Entities, Attributes, Super Types, Sub Types, Primary Key, Alternate Key, Inversion Key Entry, Rule, Relationship, Definition, business rule, etc
Physical Data Model :
1.The Physical data model is nothing but the representation of a physical database.
2.Physical data model includes all required tables, columns, relationship, database properties for the physical implementation of databases.
3.Database performance, indexing strategy, and physical storage are important parameters of a physical model.
4.The important or main object in a database is a table which consists of rows and columns. The approach by which physical data models are created is called physical data modeling.
78. What is database normalization?( 100% asked Data Modeling Interview Questions )
Ans:
Database Normalization is nothing but a technique of designing the database in a structured way to reduce redundancy and improve data integrity.
Database Normalization is used for following Purpose:
- 1. To Eliminate the redundant or useless data
- 2. To Reduce the complexity of the data
- 3. To Ensure the relationship between tables as well as data in the tables
- 4. To Ensure data dependencies and data is logically stored.
79. What are different check points for normalizing data?
Ans:
There are following checkpoints to normalize the data :
1.Arrangement of data into logical groups.
2.Minimize the Duplicate data.
3.Organize the data in such a way that when modification is needed then there should be only one place modification required.
4.User can access and manipulate data quickly and efficiently.
80. What is the first normal form ? Explain with example.( 80% asked Data Modeling Interview Questions )
Ans:
The first normal form is the normal form of database where data must not contain repeating groups.The database is in First normal form If,
1.It contains only atomic values.
Automic values:- The Single cell have only single value
2.Each Record needs to be unique and there are no repeating groups.
Repeating Groups:- Repeating groups means a table contains 2 or more values of columns that are closely related.
Example:
Consider following table which is not normalized:
Employee Table:
| Employee No | Employee Name | Department |
|---|---|---|
| 1 | Amit | OBIEE,ETL |
| 2 | Divya | COGNOS |
| 3 | Rama | Administrator |
To bring it into first normal form We need to split the table into 2 tables.
First table:Employee Table
| Employee No | Employee Name |
|---|---|
| 1 | Amit |
| 2 | Divya |
| 3 | Rama |
Second Table: Department table
| Employee No | Department |
|---|---|
| 1 | OBIEE |
| 1 | ETL |
| 2 | COGNOS |
| 3 | Administrator |
We have divided the table into two different tables and the column of each table is holding the atomic values and duplicates also removed.
81.Explain Second Normal Form with example.( 80% asked Data Modeling Interview Questions )
Ans:
The data is said to be in second normalized form If,
1.It is in First normal form
2.There should not be any partial dependency of any column on primary key.Means the table has a concatenated primary key and each attribute in the table depends on that concatenated primary key.
3.All Non-key attributes are fully functionally dependent on primary key.If primary is not composite key then all non key attributes are fully functionally dependent on primary key.
Example:
Let us consider following table which is in first normal form:
| Employee No | Department No | Employee Name | Department |
|---|---|---|---|
| 1 | 101 | Amit | OBIEE |
| 2 | 102 | Divya | COGNOS |
| 3 | 101 | Rama | OBIEE |
In above example we can see that department .Here We will see that there is composite key as{ Employee No,Department No}.Employee No is dependent on Employee Name and Department is dependent on Department No.We can split the above table into 2 different tables:
Table 1:Employee_NO table
| Employee No | Department No | Employee Name |
|---|---|---|
| 1 | 101 | Amit |
| 2 | 102 | Divya |
| 3 | 101 | Rama |
Table 2:Department table
| Department No | Department |
|---|---|
| 101 | OBIEE |
| 102 | COGNOS |
Now we have simplified the table into a second normal form where each entity of the table is functionally dependent on the primary key.
82. Explain Third Normal Form with example.( 80% asked Data Modeling Interview Questions )
Ans:
The database is in Third normal form if it satisfies following conditions:
1.It is in Second normal form
2.There is no transitive functional dependency
Transitive Dependency:
When table 1 is Functionally dependent on table 2. and table 2 is functionally dependent on table 3 then.table 3 is transitively dependent on table 1 via table 2.
Example:
Consider following table:
| Employee No | Salary Slip No | Employee Name | Salary |
|---|---|---|---|
| 1 | 0001 | Amit | 50000 |
| 2 | 0002 | Divya | 40000 |
| 3 | 0003 | Rama | 57000 |
In above table Employee No determines the Salary Slip No.And Salary Slip no Determines Employee name.Therefore Employee No determines Employee Name.We have transitive functional dependency so that this structure does not satisfy Third Normal Form.
For That we will Split tables into following 2 tables:
Employee table:
| Employee No | Salary Slip No | Employee Name |
|---|---|---|
| 1 | 0001 | Amit |
| 2 | 0002 | Divya |
| 3 | 0003 | Rama |
Salary Table:
| Salary Slip No | Salary |
|---|---|
| 0001 | 50000 |
| 0002 | 40000 |
| 0003 | 57000 |
Following are 2 Advantages of 3rd normal form:
1.Amount of data duplication is removed because transitive dependency is removed in third normal form.
2.Achieved Data integrity.
83. Explain Boyce Codd Normal Form with example.( 50% asked Data Modeling Interview Questions )
Ans:
BCNF Normal form is a higher version of third normal form.This form is used to handle anomalies which are not handled in third normal form.BCNF does not allow dependencies between attributes that belong to candidate keys.It drops restriction of the non key attributes from third normal form.
Third normal form and BCNF are not same if following conditions are true:
1.The table has 2 or more candidate keys
2.At least two of candidate keys are composed of more than 1 attribute
3.The keys are not disjoint.
Example:
- Address-> {City,Street,Zip}
- Key 1-> {City,Zip}
- Key 2->{City,Street}
- No non key attribute hence this example is of 3 NF.
- {City,Street}->{zip}
- {Zip}->{City}
There is dependency between attributes belonging to key.Hence this is BCNF.
84. What is the Dimension table? Explain with example.( 100% asked Data Modeling Interview Questions )
Ans:
Dimension table is table which describes the business entities of an enterprise which describes the objects in a fact table.Dimension table has primary key which uniquely identifies each dimension row.Dimension table is sometimes called as lookup or reference table.The primary key of dimension table is used to associate relationship between fact table which contains foreign key.Dimension tables are normally in de-normalized form because these tables are only used to analyse the data and not used to execute transactions.
The fields in a dimension table is used to complete following 3 important requirement :
- 1. Query Constrainting
- 2. Grouping /Filtering
- 3. Report labeling
Real Life Example :
Consider the following table which contains item information.In the following table ITEM KEY is the primary key which uniquely identifies the rows in the dimension table. ITEM KEY will be present in the Fact table.
| ITEM KEY | ITEM NAME | BRAND | SOLD BY | Category |
|---|---|---|---|---|
| 00001 | Yellow shirt | Yazaki | Amit | Shirts |
| 00002 | Football | Start sports | Rahul | Sports |
| 00003 | Blue Shorts | Puma | Amit | Shorts |
In the image I have explained which are facts and which are dimension tables. You will able to see there are four dimensions :
1.Time
2.Location
3.Item
4.Branch
85. Explain What is Aggregate table with Example.( 100% asked Data Modeling Interview Questions )
Ans:
Aggregate table contains aggregated data which can be calculated by using different aggregate functions like count,avg,min,max.e.t.c.Aggregated tables are most widely used tables in OLAP database.Aggregate functions are functions where the values of table or column are grouped together and form a single value. Following are some aggregate functions:
1.Average
2.Count
3.MAX
4.MIN
5.Median
6.SUM
Using the above aggregate functions the data will be inserted in aggregate table.The aggregate tables are used for performance optimization and data is coming fast using aggregate table.Aggregations applied on database level improves the performance of the query as the query not hits directly on table it will hit on aggregate table and fetches data.
Real Example:
If table contains the data of year 2016 and 2017 ,User wants a actual count of records in the table monthly,Quarterly and yearly.Then We need to make aggregate table which contains count of records monthly,For Quarterly we need to create other table and push the quarterly count in that table.And we need to use that tables in the reports so that report performance will improve drastically.
86. Explain Primary key with example.
Ans:
The SQL PRIMARY KEY Constraint Uniquely identifies each record in a database table.
PRIMARY KEY must contain unique values. A Primary Key column cannot contain NULL values. Each table can have only ONE PRIMARY KEY.
Example :
- CREATE TABLE Student
- (
- RollNo Number (10),
- FName Varchar2 (15),
- LName Varchar2 (15),
- Location Varchar2 (10),
- CONSTRAINT PK_Student_FName_LName PRIMARY KEY (FName, LName)
- );
87. Explain SQL Check Constraint.
Ans:
The CHECK constraint is used to limit the value range that can be placed in a column.
If you define a CHECK constraint on a single column it allows only certain values for this column.
If you define a CHECK constraint on a table it can limit the values in certain columns based on values in other columns in the row.
Real Life Scenario:
- CREATE TABLE Student
- (
- Class Number (5),
- RollNo Number (10),
- Subject Varchar2 (15),
- Fees Number (10, 2) CHECK (Fees>500)
- );
- CREATE TABLE Student
- (
- Class Number (5),
- RollNo Number (10),
- Subject Varchar2 (15),
- Fees Number (10, 2) CHECK (Fees>500)
- );
In the above example we have added the Check constraint for Fees column.
88. What are different types of Schema used in Data Modeling?
Ans:
There are two types of schemas used in Data Modeling:
- 1. Star Schema
- 2. Snowflake Schema
89. Explain Star Schema with Example.
Ans:
In Star schema there is Fact table as a center and all dimension tables surrounded with that fact table.It is called as Star schema because diagram resembles a star with points radiating from center.Star schema is used in simple data mart or data warehouse.Star schema is designed in such way that it will optimize the querying on large data sets.In Star schema multiple dimension tables joined with only one fact table in denormalized form.
Real Life Example :
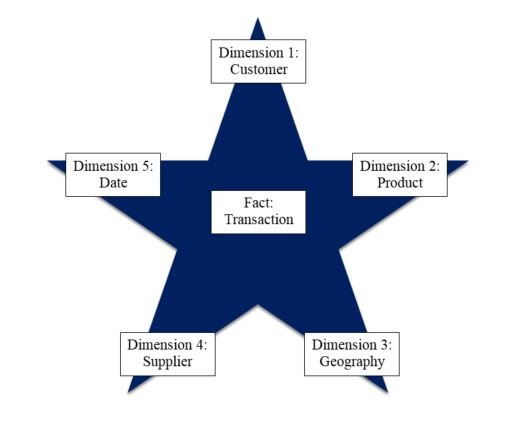
In the above diagram you will be able to see that the table named transaction is fact table and all 5 are Dimension tables.
90. Explain Granularity.( 100% asked Data Modeling Interview Questions )
Ans:
Granularity in table represents the level of information stored in the table.In BI granularity is very important concept to check the table data.The granularity is high and low .High granularity data contains the data with high information or you can say it as transaction level data is high granularity data.Low granularity means data has low level information only.Fact table always have low granularity mean we need very low level data in fact table.
Following 2 points are important in defining granularity :
1.Determining the dimensions that are to be included
2.Determining location to place hierarchy of each dimension of information.
Real life Example :
Date Dimension Granularity level :
Year,month,quarter,period,week,day.
91. Explain Snowflake Schema with example.
Ans:
Snowflake schema is a form of dimensional modeling where dimensions are stored with multiple dimension tables.Snowflake schema is variation over star schema.The schema is diagrammed as each fact is surrounded with dimensions;and some dimensions are further related to other dimensions which are branched in snowflake pattern.In snowflake schema multiple dimension tables are organized and joined with fact table.Only difference between star and snowflake schema is dimensions are normalized in snowflake schema.
Real life Example :
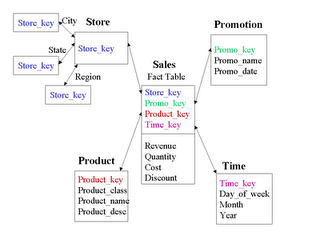
In Diagram I showed the snowflake schema where the sales table is a fact table and all are dimensions.Store table is further normalized into different tables named city,state and region.
92.Explain Difference between OLTP and OLAP?( 100% asked Data Modeling Interview Questions )
Ans:
Following Table shows difference between OLAP and OLTP system:
| OLAP | OLTP |
|---|---|
| Data Storage:It stores only historical data and historical data processing is done. | Data Storage:It involves daily processing of data |
| Users Of System:OLAP System is used by higher management like managers , analysts , executives,CEO,CFOs | Users Of System:OLTP system used by DBAs, Database Professionals ,Programmers for applying business logic. |
| Key use:OLAP is used to analyse the business | Key use:OLTP is used to run the business |
| Optimization Techniques:OLAP is very huge database so lot of indexes are used for fast data processing | Optimization Techniques:OLTP uses less indexing as data is less here |
| Database Schema:OLAP uses Star-Schema,Snowflakes schema or Fact-Dimensions | Database Schema:OLTP uses Entity Relations |
| Data Information:OLAP contains historical data | Data Information:OLTP contains Current data |
| Join Data:OLAP has less joins and in de-normalized form database | Join Data:OLTP has large no of joins and in normalized form |
| Aggregated Data:OLAP system has aggregated multidimensional data | Aggregated Data:OLTP has not aggregated data. |
| Summarized data:OLAP system gives Summarized consolidated data | Detailed Data:OLTP system gives data in detailed format |
| Data Size:OLAP database size is 100 GB to 100 TB | Data Size:OLTP database size is 100 MB to 100 GB |
93. Explain Hierarchies in data modeling with its types.
Ans:
Hierarchies are series of many to one relationships which have different levels.
There are 2 types of Hierarchies :
1.Level Based Hierarchies
2.Parent Child Hierarchies
94. Explain what is meant by Conformed dimension.
Ans:
A Dimension that is utilized as a part of different areas is called a conformed dimension. It might be utilized with different fact tables in a single database or over numerous data marts/warehouses. The Conformed dimension is the dimension which is connected to two or more fact tables.
Real Life Example:
If Order table is connected to product fact as well as Order item fact and user needs to fetch data from both tables then Order dimension will be joined to Product as well as Order item table.
95. What is Slowly Changing Dimensions? Explain with Example.( 100% asked Data Modeling Interview Questions )
Ans:
Slowly Changing dimensions are dimensions which are used to manage both historical data as well as the current data in data-warehousing.
There are following different types of Slowly changing dimensions:
SCD Type 0 :
There are some attributes which will not be changed at any point of time called Type 0 SCD.
Example :
DateofBirth is the best example of SCD Type 0 which will not change at any point of time.
SCD Type 1: These are the dimensions where the previous value of the attribute is replaced by the current value. The Historical data is not maintained in SCD Type 1.
Example :
The History is not maintained in SCD Type 1. If Employee has changed the location then the location will be updated to the current location.
SCD Type 2: These are dimensions in which the historical value of attribute is preserved in column and new value is updated with insert statement.The new columns needs to be added to achieve this.
Example :
The History is not maintained in SCD Type 1. If Employee has changed the location then location will be updated to current location.Here the location is not updated the new columns like Start date and end date are created and if the Employee has changed the location on specified date it will add that date and for the second record End date is blank.
SCD Type 3 :These are the types of dimensions where limited history is preserved. And we use an additional column to maintain the history.
Example:
If Employee has changed the City then a new column will be added as a new city and in that column the new city is added and the old city name is preserved in the City column.
96. Explain what is data mart.
Ans:
Data Mart is a simplest set of Data warehouse which is used to focus on a single functional area of the business.We can say Data Mart is a subset of Data warehouse which is oriented to a specific line of business or specific functional area of business such as marketing,finance,sales e.t.c. The data come into Data Mart by different transactional systems,other data warehouses or external sources.
Data Mart is simply a subset of Organization’s Data warehouse.
97. Explain Data Mart Vs Data Warehouse?
Ans:
| Data warehouse | Data mart |
|---|---|
| Data warehousing is subject oriented, time variant, non-volatile collection of data which is used for creation of transactional reports as well as historical reports. | Data Mart is simply a subset of Organization’s Data warehouse |
| Definition:The Data Warehouse is a large repository of data collected from different organizations or departments within a corporation. | Definition:The data mart is the only subtype of a Data Warehouse. It is designed to meet the needs of a certain user group. |
| Focus:Data warehouse focuses on multiple business areas. | Focus:Data mart focuses only on a single subject area. |
| Usage:It helps to take a strategic decision. | Usage:The data mart is used to make tactical decisions for growth of business. |
| Type of system :This is a centralized system where one fact is at the center surrounded by dimension tables. | Type of system :Data mart system is decentralized system |
| Scope of Business:The Data warehouse will cover all business areas. | Scope of Business:The scope of Data mart is within the line of the Business. |
| Data Model:Data warehouse always follows top-down model | Data Model:Data mart always follows a bottom-up model. |
| Data Size: Data warehouse contains all historical data so the database size is large.Approximate size of data warehouse is greater than 100 GB. | Data Size: Data mart contains data with only one business area so the size of the database is smaller than the data warehouse. |
| Source: Data warehouse data comes from multiple heterogeneous data sources. | Source: Data mart data is data of only one business area.Many times it will come from only one data source. |
| Implementation Time: Data warehouse contains all data which will come from multiple data sources. It will take time to build a data warehouse. The Time to build a data warehouse is months to years. | Implementation Time: Data mart is a small data warehouse which will contain the data of only a single business area. The implementation time to build data mart is in months. |
98. Explain Common Errors you faced while doing data modeling?
Ans:
There are following common errors user will face while doing data modeling:
- Building Large Data Models: Building large data models is not a good practice. If tables are more than 200 the data model becomes more and more complex. In that case that data model will fail.
- Unnecessary Surrogate keys: Surrogate key should not be used unnecessarily. Use a surrogate key only when the natural key cannot serve the purpose of a primary key.
- Purpose Missing: There are so many situations where the user does not know the purpose of the business. If a user does not have proper understanding of the specified business there is no way to create a specified data model for that business. So there is a need to know the purpose of the business before creating a data model.
- Inappropriate Denormalization : Don’t denormalize until and unless you have a solid & clear business reason to do so because denormalization creates redundant data which is difficult to maintain.
These are some most important Data Modeling interview Questions with Answers. If You like this article or if you have any suggestions with the same kindly comment it in comment section